AI is not a simple discipline. The development and debugging of AI algorithms does not have a unified platform and language that integrates a large number of APIs for convenient calls. The current artificial intelligence development platform is still in a semi-barbarian state. Many functions need to be built and implemented by themselves.
Fortunately, this area has received enough attention, so many giants have developed their own platform for it, including Google's Tensorflow. Google DeepMind's accomplishments in the AI ​​field are well known. The development of this development language platform can not help but think about it. So, how does Tensorflow fit for development? Can you bring better opportunities for your research or product?
In this open class session, we invited Dr. Li Jiabo, the head of the machine learning laboratory of the technology company Nielsen, who led the team to successfully use the company’s accurate advertising push service based on Tensorflow’s own improved algorithm. In the industry for more than a decade, Dr. Li has always adhered to the combination of academic research and industrial applications, long-term close cooperation with the academic community, and the introduction of academic achievements into software innovation.
Guest introduction, Li Jiabo, currently working at the Machine Learning Lab of Nielsen, a US technology company, is responsible for leading the research and development of smart products based on deep learning, mainly using Tensorflow framework to build a new type of deep neural network, using GPU to train various user classification models, and These models are used in precision advertising. Prior to joining Nielsen last year, he worked for biotech, pharmaceutical and financial software companies including Accelrys, Schrödinger, and TD Ameritrade.
Dr. Li has always adhered to the combination of academic research and industrial applications in the industry for more than a decade. He has maintained close cooperation with the academic community for a long time and has brought academic results directly into software innovation. He is now a visiting professor at the School of Pharmacy, Sun Yat-sen University, and he directs the research topics of doctoral students. He also has an advanced seminar on Advanced Lectures on Algorithms and High Performance Computing. In addition, he published more than 60 scientific papers in international journals. Dr. Li has the ultimate pursuit of various complex scientific computing algorithm problems and invented a series of excellent algorithms in different disciplines.

â–Ž why did choose Tensorflow as the preferred platform?
At the beginning, it was uncertain as to which deep learning platform to choose, and Tensorflow was not yet available at that time. The main considerations at that time were the maturity of the platform, the programming languages ​​supported, the support and efficiency of the GPU, the ease with which to use a neural network, the ease of getting started, the subsequent development of the platform, the development of the ecological environment, and the efficiency of the platform. . Although we have collected some rating materials, it is not easy to choose among the many factors, and it is not realistic to try one by one. Soon after, Tensorflow was open sourced from Google, and we chose it without hesitation.
First, TF has all the features we require (C++/Python language support, GPU, etc.). More importantly, we believe that the platform launched by Google will quickly accept and quickly form a corresponding development ecosystem and active follow-up development. Later facts also confirmed our expectations. The following table compares several popular platforms. The data comes from the arXiv paper published in February this year.
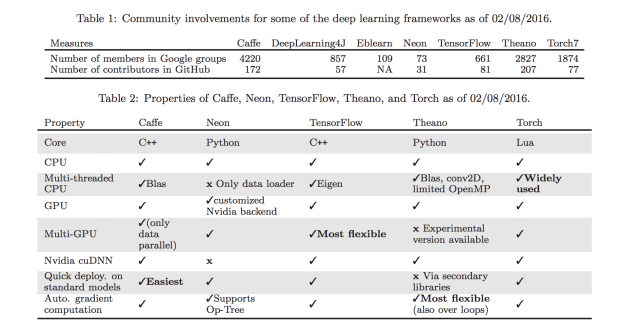
At that time, Caffe and Theano were the most active open source development community, but Tensorflow has been the most developers . See the table below:

Overall, TF feels good to me, and I believe that Google's products have the advantage of being late.
What are the advantages and disadvantages of Tensorflow?
In general, the Tensorflow provided API has enough freedom to build a neural network. The construction of the loss function is also straightforward, and the TF framework can automatically calculate the derivative of the arbitrarily constructed loss function. The training of model parameters also provides some of the latest algorithms to choose from. The TF User Forum is also very active, and difficult questions can quickly get help from it.
Of course there are some deficiencies. For example, if you want to construct an arbitrary connected neural network, TF does not improve the direct tools, but there is a workaround through vector transpose, but the cost is training and scoring are very slow.
Another disadvantage is that it is inefficient for real-time applications that require individual calculations on a single input. For example, assigning a thousand input records as a batch to TF scores is a hundred times faster than counting a thousand records each time. This means that the latter (real-time application) is two orders of magnitude less efficient than its former counterpart.
What is the difference between it and ResNet? Where are the differences between the two versions?
He Yongming’s 152-layer deep-depth residual network submitted at the end of last year won the 2015 ImageNet competition championship, followed by a paper published on arXiv ( "Deep Residual Learning for Image Recognition", by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian. Sun. (Dec. 10 2015) http://arxiv.org/abs/1512.03385 ).
In July of this year, the sequel was also published on arXiv ( "Identity Mappings in Deep Residual Networks", by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. (July, 2016) http://arxiv.org/abs/1603.05027v3 ). Here is the former ResNet I, the latter ResNet II. The starting point of the residual network is simple, and simplicity is the reason for the popularity.
The core idea consists of three elements: shortcuts for information access, residual units, residual unit output, and information channel integration . Mathematical expression is:
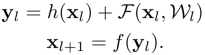
Where F is the operation of the residual unit and h(x) = x. The difference between ResNet I and ResNet II lies in the f function. If f is a nonlinear transformation, it is ResNet I, if f is an identity transformation, it is ResNet II, see the following figure:
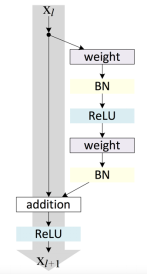
Figure 2a. The tensor flow chart of ResNet I.
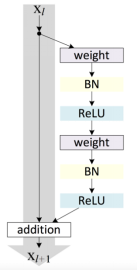
Figure 2b. The tensor flow chart of ResNet II.
Summing up: ResNet I merges immediately after the information is merged, and ResNet II transforms after the nonlinear transformation.
Why should you build your own ResNet-based network on Tensorflow?
First of all, there is no ready-made network architecture that can completely meet the solution of our problems. This is a practical need. At the same time, in order to obtain the best results, we must absorb and innovate the latest research results. We must understand why ResNet can start effectively with the idea of ​​using ResNet in applications. Although Ming Ming has a little explanation, here I give an understanding of different perspectives. The accuracy of a neural network model is affected by two competing factors: the higher the complexity of the network, the stronger the expressive power of the model and the higher the potential for reaching the best result .
On the other hand, the higher the complexity, the more difficult it is to find the best solution from the high-dimensional parameter space through the SGD method. SGD can be optimized analogy from the mountain down the mountain to the valley of the process, as shown (picture from the Internet):
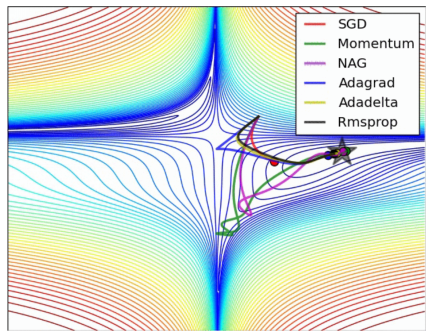
Figure 3. Stochastic Gradient Descendent (SGD) method
It can be understood this way: The optimization problem can be understood as finding a way to reach the valley from the bumpy mountain road. The mountainous road is full of traps. It is only in a high-dimensional (multi-million-dimension for three-dimensional) mountain relative to the neural network model, and the rugged complexity of mountain roads and the number of traps are far beyond the three-dimensional space. To successfully reach the valley (or close to the valley), you must try to avoid going astray and fall into traps on the way downhill. If you fall in, you will have the opportunity to escape. The structure of ResNet is based on the existing network and adds an information path shortcut so that it can be merged with the original output at a few layers forward across several layers of the network and used as the input for the next residual unit. From a mathematical intuition, it should be that the potential energy surface has become even, even if the mountain falls into a trap, the chance to escape from it is also greater.
Once you understand ResNet's ideas, you can use it in other network architectures, and this is easy to implement on Tensorflow .
The Python API provided by Tensorflow can be used directly to build the network. These APIs are very intuitive, and can translate the mathematical representation of the network structure directly into calls corresponding to tf functions (eg tf.nn.matmul, tf.nn.relu, tn.nn.l2_loss for L2 regularization, and tf.reduce_sum for L1 regularization ). Since TF can automatically calculate the derivative of any loss function, it is possible to design any form of loss function and arbitrary network structure, which is very flexible.
The introduction of ResNet allows us to build ultra-depth neural networks without having to worry too much about the problem of convergence in training models. Even for networks that are not too deep, ResNet can improve convergence and improve accuracy.
What should you pay attention to when using Tensorflow?
There is nothing special about using Tensorflow with other frameworks. However, there are problems with the universality of neural network training.
First, training neural networks often have many macro control parameters, including the depth, width of the network structure, the choice of the learning rate and dynamic adjustment, the type and intensity of regularization, the number of iterations, and so on. There are no simple criteria for how to choose a district. Usually, you can only find the best answer through continuous trial and error. The initialization of the parameters in the model is also very critical, such as improper selection, the iteration will stagnate. For example, if the optimization is stalled, the simple solution is to scale all the starting parameters.
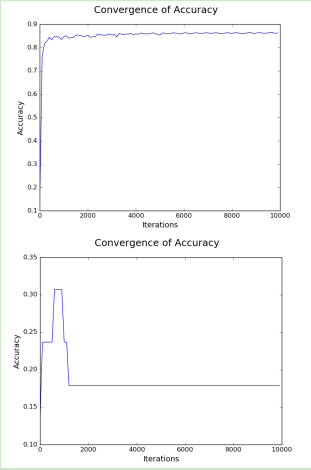
Figure 4. Convergence is very sensitive to both learning rate and model initialization.
The previous figure starts to learn at a rate of 0.002, and the model training converges normally. The second figure starts to learn at a rate of 0.02 and does not converge at all.
How to build a new neural network architecture based on Tensorflow?
Constructing a neural network on Tensorflow is still relatively straightforward, because Tensorflow provides a very rich API (Python and C++), and builds various components of a neural network, including convolutional network components, various optimization methods, and combinations of various loss functions. , regularization control, etc. Therefore, many software developments can be based on the Python application interface provided by Tensorflow. Therefore, different architectures can be quickly tested in R&D.
However, precisely because of the use of Python interfaces, this may be a bottleneck for efficiency for specific applications. I have not yet gone deep into the bottom of C++ to modify Tensorflow. But in the long run, it is necessary to enter the bottom of the expansion, especially for the optimization of specific applications. For example, for a real-time application, it is required to be able to quickly respond to each individual input and return the result. We have found that while the Tensorflow GPU version is capable of high-speed batch scoring, if the same number is processed individually, the efficiency may be two orders of magnitude slower, which is a problem for real-time applications. The solution can be to write an efficient scoring function separately without having to rely on Tensorflow.
Before you mentioned that the network architecture you built is different from the convolutional neural network, so you use the idea of ​​ResNet. ReNet thinking refers to?
This problem should be seen in this way: the concept of a parallel between ResNet and ConvNet is not mutually exclusive.
The basic idea of ​​ResNet can be combined with a convolutional neural network and can be combined with any other type of neural network. The core idea of ​​ResNet is to change the condition of the potential energy surface of the loss function without changing the expression and complexity of the network, so as to make the optimization to the optimal point a smoother path.
â–Ž How to develop deep learning products according to your needs?
This problem is very big and somewhat general. In general, not all applications require deep learning. Problems that can be solved with simple models never use complex depth models. For example, if the problem can be achieved with a linear model, then using a deep neural network is not necessary because the efficiency of the simple model is much higher. However, if the problem is highly nonlinear and there is a strong coupling between variables, then using a neural network may be a good choice. But even so, we must start with a simple network, such as 3-6-tier network, and then gradually increase the number of layers, carefully observe whether there is room for improvement. Since the SGD optimization results have certain errors and uncertainties, the results of each Tensorflow optimization will have certain differences. Therefore, it is necessary to be careful when observing the increase in the number of layers to improve the accuracy of the model. It is necessary to repeat multiple calculations and average values. Then make a comparison. This is especially important when the number of samples is small.
â–Ž How to do algorithmic innovation in deep learning according to your needs?
This is a big problem. You should ask Jeff Hinton or Yan LeCun and other big cattle. However, some common innovative ways of thinking are worth learning from. In my opinion, we must first have a thorough understanding of the issue. For example, our company hopes to work on how convolutional neural networks work. In recent years, there has been an in-depth understanding of how to improve the accuracy of algorithms in continuous improvement. Not only that, we also need to understand the results of research in the opposite direction. For example, studies by Szegedy et al. showed that adding a picture that can be completely correctly recognized by a DNN model (such as a lion) to noise that is invisible to the human eye and then letting the computer recognize it would be considered a completely different category.
There is also a recent Yoshinski study showing that using a trained DNN model, from a totally random television picture of snowflake noise (nothing at all), the DNN is thought to have a high degree of confidence (99.99%) by optimizing the image. The image obtained by a particular animal (such as a panda or a woodpecker, etc.) is still like a piece of noise and does not show any meaningful appearance at all.

If we can understand these phenomena mathematically, then we must generate new ideas, guide us to try new network structures, and find more efficient, more accurate, and more robust algorithms. However, we still do not know enough about these issues, and precisely because of this, there are many innovative spaces waiting for us to discover. In addition, most current algorithms for image recognition are based almost exclusively on convolutional neural networks. Are there other ways that we can train good models even with fewer samples, just as humans do? This is worth our deep thinking!
How do you improve your neural network based on your needs?
How to improve the network architecture according to their own needs is more general. Generally speaking, it should be adjusted according to the particularity of its own application. For example, a convolutional neural network is mainly used for image recognition because each pixel in the image is associated with its neighboring pixels, and all of this association, spatial relationship, determines the characterization of an image. The convolutional neural network is designed to extract these features and train the model through numerous examples.
In some problems, the interaction between variables is not clear and it is impossible to apply a convolutional neural network. In this case, a fully connected network can be used, or network connections can be established based on known or guessed interactions (this can greatly reduce the amount of parameters). Practical applications also involve model efficiency (speed) issues. If a neural network is too large, it will be slow to train or score. If you need to speed up, you must reduce the size of the model.
How to use GPU acceleration? Please give examples.
For Tensorflow, its GPU acceleration has been implemented at the bottom of its core architecture. There are corresponding GPU versions for the relevant neural network operations, so from a developer's point of view, Tensorflow has actually freed developers from the pain of GPU programming. Therefore, using GPU acceleration becomes just an installation issue.
If you have a GPU machine, load the version of Tensorflow that supports the GPU. The CPU/GPU version is transparent from the API perspective, and the same PYTHON code can run on both CPU/GPU versions.
However, one thing to note when installing a GPU version is that Tensorflow requires a GPU card with 3.5 or more GPUs by default. If your GPU's computing power is 3.0 (very common), there will be problems with the default installation. At this time, compile and install from the source code, and set the compile time option to 3.0. At present, the GPU provided by Amazon Cloud Computing is still 3.0, so installing Tensorflow on Amazon starts from the source code. Tensorflow supports multiple GPUs, but the corresponding code has to be modified because of the programming of task assignments. We compared the speed of a 32-core CPU with Tensorflow running on a single-chip GPU machine. The GPU machine is about 4 times the speed of a 32-core CPU machine.
How do you stick to scientific research for many years and incorporate the results into software innovation?
It takes a lot of enthusiasm to adhere to the academic achievements in software innovation for many years.
I have always been interested in academic research, especially related to practical applications. The purpose is to integrate breakthrough research results into the development of new products. For example, 2006 won the company’s academic leave, which gave me a few months of free scientific research opportunities. It was during this period that we invented the CAESAR algorithm to improve the efficiency of three-dimensional molecular structure simulation by more than ten times. And as a core module of drug molecule design, it is widely used in pharmaceutical research and development of major pharmaceutical companies. Beginning in 2008 with Sun Yat-Sen University, in addition to providing long-distance education to domestic graduate students, he returned to China once or twice a year to teach and guide graduate students.
Another success story: WEGA (Gaussian weights for 3D geometry comparison) algorithm.
Industrial Applications: Computer-aided Design of Drug Molecules
The pain point of the problem: the huge-scale molecular library, the calculation of billions of billions of molecules, is computationally intensive and time-consuming.
Cooperative research: In cooperation with the School of Pharmacy of Sun Yat-sen University, a research team was established, including a Ph.D. student and his students.
Solution: There are three steps: 1) new algorithm, 2) GPU acceleration, and 3) massive parallelism of GPU clusters.
Research results:
1) In terms of algorithms, a WEGA (Gaussian weight) algorithm that compares the three-dimensional shape of molecules is proposed, which greatly improves the calculation accuracy while retaining the simplicity and high efficiency of calculation.
2) Instructing doctoral students of Zhongda University to develop GWEGA that utilizes GPU acceleration so that the single-chip GPU can be accelerated by nearly 100 times.
3) Utilizing the GPU cluster of Guangzhou Supercomputer Center to achieve large-scale GPU parallelization, the 3D structure retrieval of the TB-order ultra-large-scale molecular library was transplanted to the GPU cluster, achieving a high-throughput drug molecule virtual screening of 100 million times per second. , nearly two orders of magnitude faster than international competitors. This result we applied for Chinese and international patents.
Difficulties: The difficulty of this project is GPU programming. The threshold of GPU programming is high, especially to achieve high efficiency, especially to achieve nearly 100 times the acceleration, and there are strict requirements for programming skills. To this end, special GPU programming courses for graduate students from the Middle East have been set up to allow students to get started quickly, and then have a deep understanding of the GPU architecture. Key areas are discussed with students. Each line of code is analyzed and optimized one by one, and the efficiency is pushed to the extreme. This process not only trains students, but also solves difficult problems.
â–Ž Group friends question: In addition to images, for other signals that have certain interrelatedness, can we learn from convolutional networks, such as machine learning that has some related signals in time?
Yes, but it's too much trouble because you don't know how to classify it. For audio, time and frequency make up a two-dimensional image.

Power Strip With Usb Ports,Usb Charging Strip,Power Strip With Usb Charging Ports,Multiple Usb Power Strip
Yang Guang Auli Electronic Appliances Co., Ltd. , https://www.ygpowerstrips.com