Preface: There are three main categories of artificial intelligence machine learning: 1) classification; 2) regression; 3) clustering. Today we will focus on the C4.5 algorithm.

The C4.5 algorithm is an algorithm proposed and developed by Quinlan for generating decision trees [see Artificial Intelligence (23)]. This algorithm is an extension of the ID3 algorithm previously developed by Quinlan. The decision tree generated by the C4.5 algorithm can be used for classification purposes, so the algorithm can also be used for statistical classification.
The C4.5 algorithm uses the concept of information entropy the same as the ID3 algorithm, and builds a decision tree through learning data like the ID3 algorithm. The ID3 algorithm uses the change value of information entropy, while the C4.5 algorithm uses the information gain rate. Pruning is performed during the construction of the decision tree, because some nodes with few elements may make the constructed decision tree overfitting. It may be better if these nodes are not considered. It can process non-discrete data and process incomplete data.
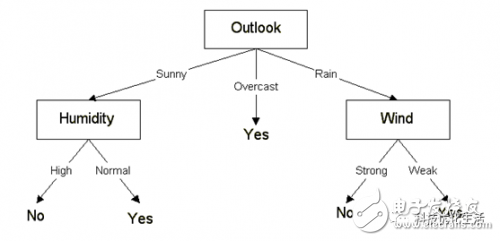
C4.5 Algorithm concept:
The C4.5 algorithm was proposed by Quinlan on the basis of the ID3 algorithm to construct a decision tree. The C4.5 algorithm is a classic algorithm used to generate decision trees. It is a series of algorithms used in machine learning and data mining classification problems. Its goal is supervised learning: given a data set, each tuple in it can be described by a set of attribute values, and each tuple belongs to a certain category in a mutually exclusive category. Through learning, find a mapping relationship from attribute value to category, and this mapping can be used to classify new entities with unknown categories.
C4.5 Algorithm improvement:
The C4.5 algorithm is an extension and optimization of the ID3 algorithm. The main improvements made by the C4.5 algorithm to the ID3 algorithm are: 1) The split attribute is selected through the information gain rate, which overcomes the deficiencies of the split attribute in the ID3 algorithm; 2) Pass Discretize continuous attributes to overcome the defect that the ID3 algorithm cannot handle continuous data; 3) After constructing the decision tree, perform pruning operations to solve the over-fitting problem that may occur in the ID3 algorithm; 4) Ability to deal with defects Training data for attribute values.
C4.5 The essence of the algorithm:
Information gain metric used by ID3. It preferentially selects Feature with more attribute values, because Feature with more attribute values ​​will have relatively larger information gain. Information gain reflects the degree of uncertainty reduction after a given condition. The more detailed the data set is, the higher the certainty, that is, the smaller the conditional entropy, the greater the information gain. One metric to avoid this deficiency is not to use information gain to select Feature, but to use information gain ratio (gain raTIo).
The gain ratio penalizes features with more values ​​by introducing a term called split information (Split informaTIon). The split information is used to measure the breadth and uniformity of the feature split data (a bit like the feeling of evenly spreading eggs in a pancake). ^).
Split information formula:
Information gain ratio formula:
But when the size of a certain Di is close to the size of D, then
SpliTInformaTIon (D, A) → 0
GainRatio (D, A)→∞
In order to avoid such attributes, heuristics are adopted, and the information gain ratio is used only for those attributes with relatively high information gain.
C4.5 Algorithm flow:The C4.5 algorithm is not an algorithm, but a set of algorithms. The C4.5 algorithm includes non-pruned C4.5 and C4.5 rules.

C4.5 can handle continuous attribute values, the specific steps are:
1) Sort the samples to be processed (corresponding to the root node) or sample subsets (corresponding to the subtree) according to the size of the continuous variable from small to large;
2) Assuming that there are N different attribute values ​​corresponding to this attribute, there are N in total? 1 Possible candidate segmentation threshold points. The value of each candidate segmentation threshold point is the midpoint of the consecutive elements before and after the above sorted attribute values. According to this segmentation point, the original continuous attribute is divided into discrete attributes (such as BooL attribute). );
3) Use the information gain ratio to select the best partition.
In addition, the C4.5 algorithm can also handle missing values:
1) Assign the most common value of the attribute;
2) Assign a probability according to the occurrence of the attribute value on the sample of the node;
3) Discard samples with missing values.
C4.5 algorithm adopts PEP (Pessimistic Error Pruning) pruning method. The PEP pruning method was proposed by Quinlan. It is a top-down pruning method, which determines whether to prun the subtree according to the error rate before and after the pruning, so there is no need for a separate pruning data set.
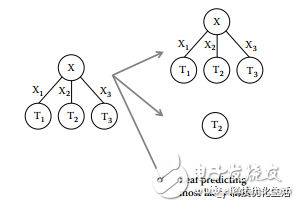
1) Select splitting attributes through the information gain rate, which overcomes the insufficiency of the ID3 algorithm that tends to select attributes with multiple attribute values ​​as splitting attributes through information gain;
2) By discretizing continuous attributes, the ID3 algorithm can not handle continuous data defects, and the C4.5 algorithm can handle two attribute types, discrete and continuous;
3) Pruning (PEP) operation (not in the ID3 algorithm) is carried out after constructing the decision tree to solve the over-fitting problem that may occur in the ID3 algorithm;
4) Ability to handle training data with missing attribute values;
5) The generated classification rules are easy to understand and have a high accuracy rate.
C4.5 Disadvantages:1) In the process of constructing the tree, the data set needs to be scanned and sorted multiple times, which leads to the inefficiency of the algorithm;
2) For training samples with continuous attribute values, the calculation efficiency of the algorithm is low;
3) The algorithm does not consider the correlation between conditional attributes when selecting split attributes, and only calculates the expected information between each conditional attribute and decision attribute in the data set, which may affect the correctness of attribute selection;
4) The algorithm is only suitable for data sets that can reside in memory, and the program cannot run when the training set is too large to fit in the memory.

The C4.5 algorithm has the advantages of clear structure, capable of processing continuous attributes, preventing over-fitting, high accuracy and wide application range. It is a very practical decision tree algorithm, which can be used for classification or return. C4.5 algorithms are widely used in the fields of machine learning, knowledge discovery, financial analysis, remote sensing image classification, manufacturing, molecular biology and data mining.
Conclusion:C4.5 algorithm is proposed by Quinlan on the basis of ID3 algorithm. The C4.5 algorithm is an extension of the ID3 algorithm, and some improvements and optimizations have been made to the ID3 algorithm. It is a series of algorithms used in machine learning and data mining classification problems. C4.5 algorithm is not an algorithm, but a set of algorithms. C4.5 The goal of the algorithm is to find a mapping relationship from attribute values ​​to categories through learning, and this mapping can be used to classify new entities with unknown categories. The C4.5 algorithm is widely circulated in the world and has received great attention. C4.5 algorithms are widely used in the fields of machine learning, knowledge discovery, financial analysis, remote sensing image classification, manufacturing, molecular biology and data mining.
Fog Light Wire Harness are most used in automotive,motocycle,bus,bike,truck,LVDs,medical equipment.
Yacenter has experienced QC to check the products in each process, from developing samples to bulk, to make sure the best quality of goods. Timely communication with customers is so important during our cooperation.
If you can't find the exact product you need in the pictures,please don't go away.Just contact me freely or send your sample and drawing to us.We will reply you as soon as possible.
Fog Light Harness,Fog Light Wiring Kit,Universal Fog Light Wiring Harness,Fog Light Wiring Harness
Dongguan YAC Electric Co,. LTD. , https://www.yacentercn.com