Hadoop is a distributed system infrastructure developed by the Apache Foundation.
Users can develop distributed programs without knowing the underlying details of the distribution. Take full advantage of the power of the cluster for high-speed computing and storage.
Hadoop implements a distributed file system (Hadoop Distributed File System), referred to as HDFS. HDFS is highly fault-tolerant and designed to be deployed on low-cost hardware; it also provides high throughput to access application data for large data sets (large data) Set) application. HDFS relaxes the requirements of POSIX and can stream access data in the file system.
The core design of Hadoop's framework is HDFS and MapReduce. HDFS provides storage for massive amounts of data, and MapReduce provides calculations for massive amounts of data.
Hadoop-based campus cloud storage systemThe server uses the Linux operating system and implements parallel processing using the MapReduce programming algorithm.
HDFS (Hadoop Distributed File System) is a distributed file system that runs on top of normal hardware. The HDFS system uses the Master/Slave framework. An HDFS cluster system consists of a Master and multiple Slavers. The former is called the NameNode. It is a central server responsible for the management of metadata. It mainly includes the file system namespace management and client access to files. The latter is called a data node. In a cluster system, a node is usually composed of a DataNode, which is mainly responsible for managing the storage attached to the node.
The directory structure of files in the HDFS system is stored separately on the NameNode. For specific file data, a file data is actually split into several blocks, and these blocks are redundantly stored in the DataNode collection data. The NameNode is responsible for performing the Namespace management of the file system, including operations such as closing, opening, and renaming data files and directories. It is also responsible for establishing mapping relationships between blocks and DataNode nodes. The read and write requirements of the client are completed by the response of the DataNode node, and the DataNode node performs the operations of creating, deleting, and copying the Block under the unified command of the NameNode.
The MapReduce programming model is a programming model that is the core computing model for cloud computing and is used for parallel computing of large-scale data sets. MapReduce borrows the idea of ​​functional programming to abstract the common operations of massive data sets into two collection operations: Map (Map) and Reduce (Simplification). The divided data is mapped into different blocks by the Map function, and then the distributed data is processed by the computer cluster, and then the data is uniformly aggregated by the Reduce function, and finally the data result desired by the user is output. The software implementation of MapReduce is to specify a Map function to map a set of key-value pairs into a new set of key-value pairs, specifying a concurrent Reduce function to guarantee each of the mapped key-value pairs. Share the same key group.
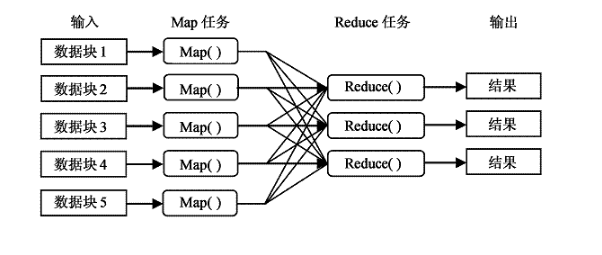
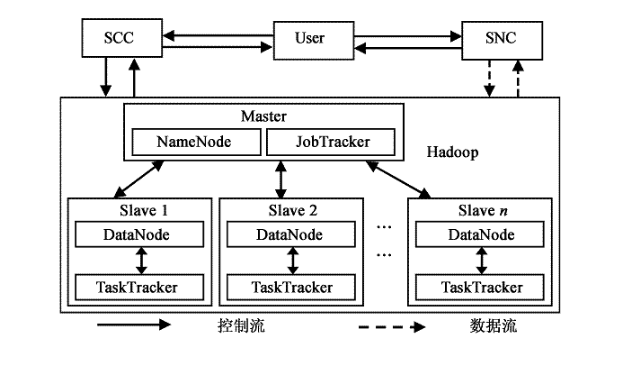
Master includes NameNode and JobTracker. Slave includes DataNodes and TaskTrackers. HDFS works mainly by NameNode and DataNodes. MapReduce works mainly by JobTracker and TaskTrackers. Model Workflow: Service Controller Cluster (SCC) is mainly responsible for receiving user application requests and completing response work according to user requests. The Storage Node Cluster (SNC) is mainly responsible for processing access to data resources. JobTracker can run on every computer in the cluster system, mainly to manage and schedule TaskTracker on other computers.
The difference is that the TaskTracker must run on the DataNode of the data storage node, mainly to perform the task. JobTracker is responsible for assigning each Map and Reduce task to the idle TaskTracker process, completing the parallel computing processing task for each data file, and monitoring the completion of each task. When one of the TaskTrackers fails, the JobTracker will actively transfer the task it is responsible to to another free TaskTracker to perform the task again. The user itself does not directly read and write data through the Hadoop architecture, which is caused by system congestion that can avoid a large number of read and write operations. When the user passes the information to the SCC through the Hadoop architecture, it will directly interact with the storage node and complete the data read operation.
The system uses Hadoop software, 7 PCs, one of which is Master, namenode (cluster master node); the other six are Slave, datanode (slave node).
Cluster deployment steps:
(1). SSH is configured in the cluster to implement password-free login between machines. Generate the ssh key on each machine, then exchange the public key, copy the namenode's public key to each datanode, so you don't need a password to access each other.
(2). Install the JDK on each machine and configure the java environment.
(3). Install and configure hadoop.
(4). Start the hadoop service.
(5). Install eclipse and build an integrated development environment.
Cloud storage based on Hadoop platformCloud Computing is an Internet-based supercomputing model in which thousands of computers and servers are connected into a single computer cloud in a remote data center. Users access the data center through computers, laptops, mobile phones, etc., and perform calculations according to their own needs. Currently, there is still no universally consistent definition of cloud computing. Combined with the above definitions, some essential features of cloud computing can be summarized, namely distributed computing and storage characteristics, high scalability, user-friendliness, and good management.
1 cloud storage architecture diagram
The orange storage node (Storage Node) is responsible for storing files, and the blue is used as the control node (the Control Node is responsible for file indexing and is responsible for monitoring the balance of capacity and load between storage nodes. These two parts are combined to form A cloud storage. The storage node and the control node are simple servers, but the storage node has more hard disks. The storage node server does not need to have the RAID function. As long as Linux can be installed, the control node needs to have a simple data to protect the data. RAID level O1 function.
Cloud storage is not a replacement for existing disk arrays, but a new form of storage system to cope with the rapid growth of data volume and bandwidth. Therefore, cloud storage is usually designed with three points in mind:
(1) Whether capacity and bandwidth expansion are simple
Capacity expansion is not downtime, and the new storage node capacity is automatically included in the original storage pool. No need to make complicated settings.
Figure 1 cloud storage architecture diagram
(2) Whether the bandwidth is linearly growing
Many customers who use cloud storage consider the future growth of bandwidth. Therefore, the design of cloud storage products will have great differences. Some dozen nodes will be saturated, which will adversely affect the expansion of future bandwidth. This must be clarified in advance, otherwise it will be too late to wait until it finds that it does not meet the demand.
(3) Is management easy?
2 cloud storage key technology
Cloud storage must have nine elements: 1 performance; 2 security; 3 automatic ILM storage; 4 storage access mode; 5 availability; 6 primary data protection; 7 secondary data protection; 8 flexible storage;
The development of cloud computing is inseparable from the development of core technologies such as virtualization, parallel computing and distributed computing. The following describes it as follows:
(1) Cluster technology, grid technology and distributed file system
A cloud storage system is a collection of multiple storage devices, multiple applications, and multiple services. Any single point storage system is not cloud storage.
Since it is composed of multiple storage devices, technologies such as cluster technology, distributed file system, and grid computing need to be used to implement collaborative work between multiple storage devices, so that multiple storage devices can be used. Provide the same service to the outside world and provide greater and better data access performance. Without the existence of these technologies, cloud storage cannot be realized. The so-called cloud storage can only be a single system, and cannot form a cloud structure.
(2) CDN content distribution, P2P technology, data compression technology, deduplication technology, data encryption technology
The CDN content distribution system and the data encryption technology ensure that the data in the cloud storage is not accessed by unauthorized users. At the same time, the data in the cloud storage is not lost through various data backup and disaster recovery technologies, and the cloud storage itself is guaranteed. Safe and stable. If the security of data in cloud storage is not guaranteed, no one dares to use cloud storage.
(3) Storage virtualization technology, storage network management technology
The number of storage devices in cloud storage is large and distributed in different regions. How to implement logical volume management, storage virtualization management, and multiple devices between different vendors, different models, and even different types (such as FC storage and IP storage) Multi-link redundancy management will be a huge problem. If this problem is not solved, the storage device will be the performance bottleneck of the entire cloud storage system, and the structure will not form a whole, and it will bring the later capacity and Performance expansion is difficult.
3 deploy Hadoop
Historically, data analysis software has become incapable of facing today's massive data, and this situation is quietly changing. A new massive data analysis engine has emerged. For example, Apache's Hadoop proves that Hadoop is one of the best in data processing and one of the open source platforms.
The cloud storage center is a data node (DataNodes) that consists of a large number of servers, which is responsible for saving the contents of files, implementing distributed storage of files, load balancing, and fault-tolerant control of files.
Here's how to use Hadoop as an experimental platform to demonstrate how to deploy a three-node cluster and test the power of MapRe-dace distributed processing. Two files are stored in the Hadoop Distributed File System (HDFS). MapReduce is used to calculate the number of occurrences of each name in the two namelist files. The program architecture design is shown in Figure 2.
Figure 2 3 node Hadoop cluster
The distribution of the NameNode master node and the DataNode slave node is as follows:
Table 1
(1) Start the Hadoop cluster
You only need to run the start-all.sh command on the master node of the NameNode. At the same time, the master node can log in to each node through ssh, and the lave node starts other related processes.
(2) MapRudce test
When both NodeNode and DataNode nodes are running normally, that is, after Hadoop deployment is successful, we prepare two list files on the NameNode master node. The contents of the list file are as follows:
4 running experiments and results
5 Conclusion
The result was the same as we expected, so that the file storage for HDFS was performed on Hadoop platform, and the amount of data in the file was counted and then displayed.
Curing Screen Protector,Hydrogel Phone Cutting Machine,Protective Film Cutter Machine,Screen Protcter Custting Machine
Shenzhen TUOLI Electronic Technology Co., Ltd. , https://www.hydrogelprotectors.com