Artificial intelligence has been in full swing in the last three years. The academic, industrial, and investment communities have worked together to develop hardware, algorithms, and data. Not only large Internet companies, but also a large number of startups and companies in traditional industries have begun to get involved. intelligent.
In 2017, the artificial intelligence industry continued the momentum of booming in 2016. So what important progress has the AI ​​industry made in terms of technology development in the past year? What are the development trends in the future? This article takes a number of areas that everyone is concerned about as a representative to summarize important technological advances in some areas of the AI ​​field.
From AlphaGo Zero to Alpha Zero: A key step towards universal artificial intelligence
DeepMind's deep-enhanced learning tools are always able to bring shocking technological innovation. AlphaGo, which was born in 2016, completely smashed the ubiquitous obsession of "the machine in the field of Go can't defeat the most powerful man", but after all, Li Shishi Still winning a game, many people still have hope for the reversal of the human turn, followed by the Master completely ruined this expectation through 60 consecutive victories of many top Go players.
In 2017, AlphaGo Zero made a further technical upgrade as the second generation of AlphaGo, and the AlphaGo generation was completely ruined. At this time, human beings are no longer qualified to play against the game. AlphaGo's general-purpose version of Alpha Zero was released at the end of 2017. Not only is Go, but for other chess games such as chess and Japanese chess, Alpha Zero also overwhelmingly defeated the most powerful AI program including AlphaGo Zero.
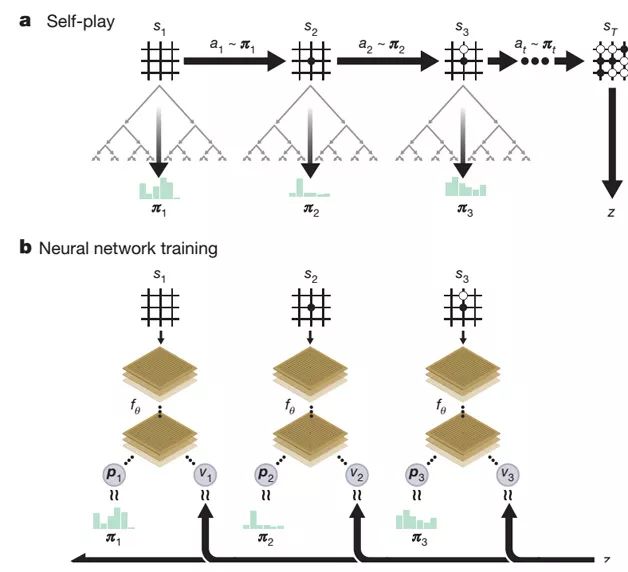
Figure 1 AlphaGo Zero's self-game and training process
AlphaGo Zero has no substantial improvement in technical means compared with AlphaGo. The main body is still the structure of MCST Monte Carlo search tree plus neural network and deep-enhanced learning training method, but the technical implementation is simple and elegant (refer to Figure 1). ). The main changes consist of two things: one is to merge AlphaGo's two predictive networks (policy network and value network) into one network, but at the same time produce two types of required output; the second is to upgrade the network structure from CNN structure to ResNet.
In spite of this, AlphaGo Zero brings no touch and inspiration to AlphaGo. The main reason is that AlphaGo Zero completely abandoned the learning experience of chess from the human chess game, starting from a blank paper through self-game. Learning, and only through three days of self-learning, I gained a Go experience that far surpassed the human millennium.
This raises a question that was generally expected by the average person but at the same time considered difficult to accomplish: can the machine evolve and learn independently of supervised training data or minimal training data? If it can really do this, does it mean that the machine will evolve rapidly and eliminate humans? The second question may even cause panic among some people. But in fact, the question itself has a problem, because it made a wrong assumption: AlphaGo Zero does not need training data. First of all, AlphaGo Zero does learn by self-game, but still needs a lot of training data, but these training data are generated by self-game. And the more fundamental point is that you should realize that for AlphaGo Zero, the essence is actually MCST Monte Carlo search. The reason why Go is difficult to overcome is that the search space is too big. It is completely unfeasible to rely solely on violent search. If we assume that there is a machine that is infinitely powerful and can quickly traverse all the search spaces, then simply using the MCST tree search, without relying on machine learning, the machine can achieve a perfect game state.
AlphaGo Zero achieves a better evaluation of the state of the board and the quality of the player through self-competition and deep-enhanced learning. It is preferred to take the path of the game with a large win, which can abandon a large number of inferior paths, thus greatly reducing the space required for search. Self-evolution is mainly reflected in the increasingly accurate assessment of the chess state. The reason why a large amount of training data can be generated by self-game is because playing chess is a task with a clear definition of rules. When it reaches a certain state, it can win or lose. It is nothing more than this final win or lose later, not every step. It can be seen that real-life tasks are difficult to achieve, which is why many tasks still require humans to provide a large amount of training data. If you consider this from the perspective, you will not mistakenly generate the above doubts.
Alpha Zero goes one step further than AlphaGo Zero and will only allow the machine to expand Go to more chess issues with clear rules, making this technology an important step toward general artificial intelligence. The technical means is basically the same as AlphaGo Zero, except that all the processing measures and technical means related to Go are removed, only the rules of the machine game are told, and then the MCST tree search + deep neural network is combined with the deep enhancement learning self-game. The unified technical program and training methods solve all chess problems.
From AlphaGo's one-step stepping strategy, DeepMind is considering the versatility of this extended technology solution, enabling it to solve more problems with a set of technologies, especially those that are of real value in non-gaming real life. problem. At the same time, AlphaGo series technology also showed the power of deep-enhanced learning to machine learning practitioners, and further promoted relevant technological advances. At present, we can also see examples of deep-enhanced learning applied in more fields.
GAN: The prospects are broad, and the theory and application are developing rapidly.
GAN, known as Generative Adversarial Nets, literally translates as "generating confrontational networks." As a representative of the generation model, GAN has attracted widespread attention from the industry since it was proposed by Ian Goodfellow in 2014. Yann LeCun, one of the deep learning masters, highly praised GAN, which is the most interesting machine learning industry in the past decade. Thoughts.
The original GAN ​​proposed by Ian Goodfellow has theoretically proved that the generator and the discriminator can reach an equilibrium state after multiple rounds of confrontation learning, so that the generator can produce ideal image results. But in fact, GAN always has problems such as difficulty in training, poor stability, and model collapse. The root cause of this mismatch is still not clear about the theoretical mechanism behind the GAN.
The past year has made encouraging progress in how to increase the stability of GAN training and solve the collapse of the model. GAN essentially uses the generator and discriminator to conduct confrontation training. The forced generator does not know the true distribution Pdata of a certain data set, and adjusts the distribution Pθ of the generated data to fit the real data distribution Pdata. It is critical to calculate the distance metrics for the two distributions Pdata and Pθ during the current training process.
The author of Wasserstein GAN pointedly pointed out that the original GAN ​​used Jensen-Shannon Divergence (JSD) in calculating the distance between the two distributions, which is essentially a variant of KL Divergence (KLD). There is a problem with JSD or KLD: when the intersection of two distributions is rare or in a low-dimensional manifold space, the discriminator can easily find a discriminant surface to distinguish the generated data from the real data, so that the discriminator cannot provide effective Gradient information is passed back to the generator, and the generator is difficult to train because of the lack of optimization goals from the discriminator. Wasserstein GAN proposed the use of Earth-Mover distance instead of the JSD standard, which greatly improved the training stability of GAN. Subsequent models such as Fisher GAN have further improved Wasserstein GAN, which has improved the training stability of GAN. The collapse of the model is also a serious problem that restricts the GAN effect. It means that after the trainer is trained, it can only produce images with several patterns fixed, and the real data distribution space is actually very large, but the model collapses into this space. A few points. In the past year, heuristic methods such as label smoothing and Mini-Batch discriminator have been proposed to solve the problem of generator model collapse and have achieved certain effects.
Although at the theoretical level, in response to the problems of GAN, the industry has proposed a number of improvements in 2017, and has a deeper understanding of GAN's internal working mechanism, but it is clear that it still does not understand its essential working mechanism. More insightful work is needed in the future to enhance our understanding of GAN.

Figure 2 Using CycleGAN to change cats in photos to dogs
GAN has a wide range of application scenarios, such as image style conversion, super-resolution image construction, automatic black-and-white image coloring, image entity attribute editing (such as automatically adding a beard to the portrait, switching hair color and other attribute transformation), between different fields of images Conversion (for example, the spring image of the same scene is automatically converted to a fall image, or the daytime scene is automatically converted to a nighttime scene), or even the dynamic replacement of the image entity, such as changing a cat in a picture or video into a dog (Refer to Figure 2).
In promoting GAN applications, there are two technologies in 2017 that are worthy of attention. One of them is CycleGAN, which uses the dual learning and GAN mechanism to optimize the effect of generating pictures. Similar ideas include DualGAN and DiscoGAN, including many subsequent improved models such as StarGAN. The importance of CycleGAN is mainly to make the model of the GAN series no longer limited to supervised learning. It introduces the unsupervised learning method. As long as two sets of pictures in different fields are prepared, there is no need to train the two fields required by the model. The one-to-one correspondence of the pictures greatly expands the scope of its use and reduces the difficulty of popularizing the application.
Another technology worthy of attention is NVIDIA's GAN program, which adopts the “progressive generation†technology route. The attraction of this solution is that it enables computers to generate high-definition pictures of 1024*1024 size, which is currently regardless of image clarity. The technology that produces the best image quality, the star image generated by it can almost achieve the effect of realism (refer to Figure 3). NVIDIA's idea of ​​coarse to fine, first generating the blurred outline of the image, and then gradually adding details is not a particularly novel idea. In the previous StackGAN and many other programs, similar ideas were adopted. It is unique in that The coarse-to-fine network structure is a static network that is dynamically generated rather than fixed in advance. What is more important is that the generated picture is particularly effective.

Figure 3 NVIDIA proposes a high-resolution avatar image generated by progressively generated GAN
All in all, the generation model represented by GAN has produced a great technical progress in both theoretical foundation and application practice in 2017. It can be expected that it will be promoted by R&D personnel at an increasing speed, and not The future will be widely used in various fields that require creativity.
Capsule: Expect to replace CNN's new structure
Capsule was published in the form of a thesis this year as Mr. Hinton, who is known as the “Godfather of Deep Learningâ€, and the paper became the focus of researchers when it came out, but in fact, this thought Hinton has been thinking deeply for a long time and has been promoting it on various occasions. This kind of thinking. Hinton has always been very interested in the Pooling operation in CNN. He once said: "The Pooling operation used in CNN is a big mistake. In fact, it works well in actual use, but it is actually a disaster." So, what is the problem with MaxPooling that Hinton hates? The reason can be seen with reference to the example shown in FIG.
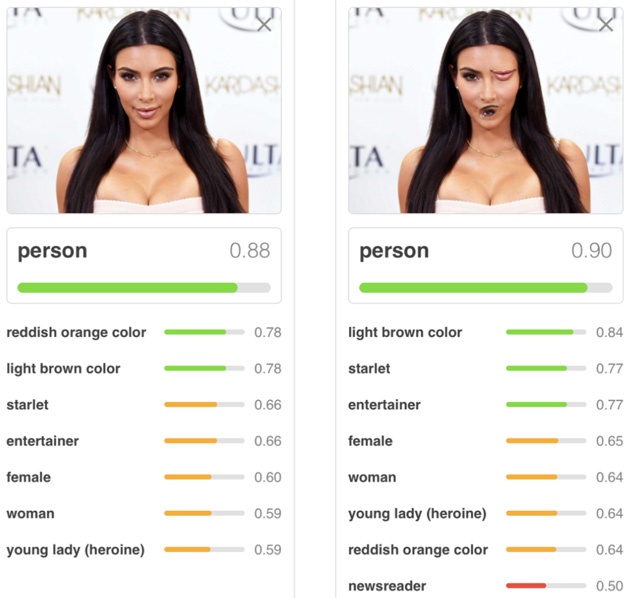
Figure 4 CNN image classification
In the above picture, two portrait photos are given, and the category of the photo and its corresponding probability are given by CNN. The first photo is a normal face photo. CNN can correctly identify the category of "human" and give a attribution probability value of 0.88. The second picture adjusts the mouth and eyes of the face to the next position. For people, it is not considered to be a normal person's face, but CNN still recognizes human beings and the confidence level does not decrease to 0.90. Why is this happening that is inconsistent with human intuition? This pot also has MaxPooling to back, because MaxPooling only responds to one of the strongest features, and it doesn't care where this feature appears and what kind of reasonable combination should be maintained between features. In short, it gives CNN "Position invariance" is too much freedom, so it results in the above judgments that are not in line with human cognition.
In Capsule's scenario, CNN's convolutional layer is preserved and the MaxPooling layer is removed. What needs to be emphasized here is that Capsule itself is a technical framework, not just a specific technology. The Hinton paper gives the simplest implementation method, which can completely create a new one under the technical idea. The specific implementation method.
It is not difficult to understand the ideas of Capsule or to implement a new technology. Just understand some of the key links to achieve this goal. If you use a sentence to explain the key points, you can use "one center, two basic points" to summarize.
One of the centers here refers to the core purpose of Capsule is to introduce the "viewing invariance" capability into the image processing system. The so-called "invariance of viewing angle" means that when we take a photo of a 3D object, the lens must be at a certain angle of the object, that is, the 2D photo reflects that the 3D object must reflect the lens and The angle of view of a 3D object, not the 360-degree object. Then, to achieve the invariance of the angle of view, you want to give a 2D photo of an object at an angle. When you see another 2D photo of the same object with different angles of view, you want CNN to recognize that it is still the object. This is the so-called "angle of view invariance" (refer to Figure 5, the upper and lower corresponding pictures represent different perspectives of the same object), which is difficult for the traditional CNN model to do well.

Figure 5 Angle of view invariance
As for the two basic points, the first basic point is to use a one-dimensional vector or two-dimensional array to represent an object or a part of the object. Although traditional CNN can also use features to represent objects or components of objects, it is often through whether different levels of convolutional layers or a certain layer of the Poing layer are activated to reflect whether a feature is present in the image. Capsule considers using more dimensional information to document and characterize feature-level objects, similar to the use of Word Embedding to characterize the semantics of a word in natural language processing. The advantage of this is that the properties of the object can be more detailed. For example, the texture, velocity, direction, etc. of the object can be used as a specific property to describe an object.
The second basic point is: the dynamic routing mechanism between different layers of neurons in Capsule, specifically the dynamic routing mechanism when low-level neurons transmit information to high-level neurons. The dynamic routing of low-level features to high-level neurons essentially reflects the idea that the components of an object will be structurally enhanced by synergistically reinforcing each other, such as the picture. The angle of view has changed, but for a human face, the components that make up the face, such as the mouth and the nose, will similarly undergo a similar perspective transformation, and they still combine to form a face that looks from another perspective. In essence, the dynamic routing mechanism is actually the feature clustering between the components that make up an object, and the components belonging to an object are dynamically and automatically found by clustering, and the "whole-part" of the feature is established. The hierarchical structure (such as the face is composed of the nose, mouth, eyes and other components).
The three aspects described above are the key to an in-depth understanding of Capsule. After the publication of Capsule's paper, a lot of attention and discussion have been triggered. At present, most people are appreciative about the Capsule computing framework. Of course, some researchers have raised questions. For example, the MINST dataset used in the paper is not large enough. The performance advantages of Capsule are not obvious, and the consumption of more memory is slow. But whether this new computing framework can replace the CNN standard model in the future, or it will soon be abandoned and forgotten, Mr. Hinton's old and firm attitude of seeking truth, and the courage to overthrow the technical system he built. The courage, these are worthy of everyone's admiration and learning.
CTR Estimate: Technology upgrades to deep learning
As a technical direction of biased application, CTR is one of the most important and most concerned directions for Internet companies. The reason is very simple. At present, most of the profits of large Internet companies come from this, because this is the most important technical means to calculate advertising direction. From the perspective of computing advertisements, the so-called CTR estimate is that for a given user User, if a certain advertisement or product Product is displayed to the user under a specific context Context, it is estimated whether the user will click on the advertisement or whether to purchase a certain Products, that is, click probability P (Click|User, Product, Context). It can be seen that this is a wide-ranging technology, and many recommended scenarios and scenarios including the current hot stream sorting can be converted into CTR estimation problems.
The commonly used technical means of CTR estimation, including the evolutionary route, is generally developed according to the path of “tree model such as LR→GBDT→FM factoring machine model→deep learningâ€. Deep learning has made rapid progress in the fields of image and video, speech, and natural language processing in recent years, but in the last one or two years, the academic community has begun to appear more frequently on how to combine deep learning with CTR prediction. Google began researching this content a few years ago, and then domestic large Internet companies began to follow up.
The CTR estimation scenario has its own unique application characteristics, and to solve the CTR estimation problem with deep learning, we must consider how to integrate and embody these features. We know that the DNN model is convenient for processing continuous numerical features, and image speech naturally satisfies this condition, but the CTR prediction scene will contain a large number of discrete features, such as a person's gender, graduation school, etc. are discrete features. So the first problem to be solved by using deep learning to do CTR estimation is how to characterize discrete features. A common method is to convert discrete features into Onehot representations, but in large Internet company application scenarios, the feature dimensions are all over 10 billion. If the Onehot representation is used, it means that the network model will contain too many parameters to learn. Therefore, the current mainstream deep learning solutions adopt the idea of ​​converting the Onehot feature representation into a low-dimensional real vector (Dense Vector, similar to Word Embedding in NLP), which can greatly reduce the parameter size. Another focus of CTR's focus is on how to automate feature combinations, because good feature combinations are critical to performance impact, and deep learning naturally has end-to-end advantages, so this is where neural network models can naturally work. Automatic identification of good feature combinations without manual intervention is generally reflected in the Deep network portion of the deep CTR model.
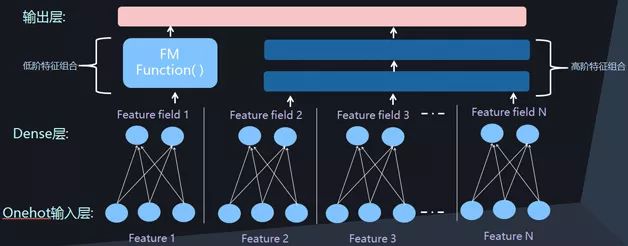
Figure 6 Parallel depth CTR network structure
Figure 7 Serial Deep CTR Network Structure
In addition to the earlier Wide&Deep models, there have been some new deep CTR models in recent years, such as DeepFM, DeepCross, and NFM models. These models, if carefully analyzed, will find that they have great similarities in the network structure. In addition to the above two characteristics in the network structure: one is the Dense Vector to represent discrete features, the other is to use the Deep network to automatically model the feature combination. Another mainstream feature is the combination of low-dimensional feature combinations and high-dimensional features on the network structure. The Deep network reflects the combination of high-dimensional features, and the neural network version of the FM model is introduced to model the two-two feature combinations. These three network structure features basically cover all current deep CTR models. Figures 6 and 7 show two common deep CTR network structures. Currently, all models basically adopt one of them.
Computer Vision: A Year of Smooth Development
Computer vision is one of the most important research directions in the AI ​​field. It itself contains many research sub-areas, including object classification and recognition, target detection and tracking, semantic segmentation, 3D reconstruction and other basic directions, as well as super-resolution. Image video description, image coloring, style migration, etc. In the current mainstream technology of computer vision processing, deep learning has occupied an absolute dominant position.
For basic research fields such as object recognition, target detection and semantic segmentation, Faster R-CNN, SSD, YOLO and other technologies are still the most advanced and mainstream technologies in the industry. Among the important emerging technologies in 2017, Facebook's He Yanming et al.'s Mask R-CNN won the best paper of ICCV2017. It improved the branch network by using Faster R-CNN, and completed object recognition and target detection. Basic tasks such as semantic segmentation, which demonstrates the possibility of using the same technology to solve multiple fundamental problems at the same time, and will facilitate the further exploration of subsequent related research; and YOLO9000 and the same He Yuming team in the paper "Learning to Segment Every Thing" The proposed MaskX R-CNN embodies another important development trend in the basic field: trying to automatically identify a wider variety of items through technical means, the ultimate goal is to be able to identify any object.
Currently MaskX R-CNN recognizes more than 3,000 categories of objects, while YOLO 9000 recognizes more than 9,000 object categories. Obviously, target detection needs to be used on a large scale in various real-world fields. In addition to high speed and accurate recognition, it is also crucial to be able to identify a large variety of object types in various real life. Research has made important progress in this regard.
From the perspective of the network model structure, 2017 did not produce a new model similar to the previous ResNet, and ResNet has been widely used in various sub-areas of visual processing because of its obvious performance advantages. Although DenseNet won the CVPR2017 best paper, it is essentially an improved model of ResNet, not a new model of new ideas.
In addition to the basic research areas of visual processing mentioned above, if the new technologies in 2017 are summarized, there are some obvious development trends in many other application areas as follows:
First, new technologies such as enhanced learning and GAN have been tried to solve many other problems in the field of image processing and have made some progress, such as Image-Caption, super-resolution, 3D reconstruction, etc., and began to try to introduce these new technologies. In addition, how deep integration and traditional methods integrate their respective advantages and deep integration is also the direction of visual processing in the past year. Deep learning technology has excellent performance, but there are also shortcomings such as unreadable black box and weak theoretical foundation. It is important to combine the advantages of the theory and the two to fully exploit their respective advantages to overcome their shortcomings. Thirdly, weak supervision, self-monitoring or unsupervised methods are becoming more and more important in various fields. This is a realistic demand. Although deep learning is effective, it is required for a large number of training data, and this requires a large amount. The cost of labeling is often not feasible in reality. The exploration of weak supervision, self-monitoring and even unsupervised methods will help to promote the rapid development of research in various fields.
Natural language processing: progress is relatively slow, urgently needed technological breakthroughs
Natural language processing is also one of the important directions of artificial intelligence. In the last two years, deep learning has basically penetrated into various sub-areas of natural language processing and made some progress, but with deep learning in the fields of image, video, audio, speech recognition, etc. Compared with the strong progress achieved, the technical dividends brought by deep learning to natural language processing are relatively limited. Compared with traditional methods, the effect has not achieved an overwhelming advantage. The reason for this phenomenon is actually a question worthy of further discussion. There are different opinions on the reasons, but there is no particularly convincing explanation that can be accepted by most people.
Compared with one year or even two years ago, the most mainstream deep learning basic technology tools currently applied in the field of natural language processing have not changed greatly. The most mainstream technical means are still the following technology combination spree: Word Embedding, LSTM (including GRU, bidirectional LSTM, etc.), Sequence to Sequence framework, and Attention attention mechanism. Combinations of these technical components and their improved variant models can be seen in a large number of natural language processing sub-fields. CNN has an overwhelming advantage in the image field, but the field of natural language processing is still dominated by RNN. Although Facebook has always advocated the use of CNN models to deal with natural language processing, except for large-scale distributed fast computing, CNN does have natural relative to RNN. In addition to its advantages, it does not currently have other unique advantages to replace the dominant position of RNN.
In recent years, deep learning has been applied in the field of natural language processing with several development trends worthy of attention. First, the integration of unsupervised models and Sequence to Sequence tasks is an important development and direction. For example, the paper "Unsupervised Machine Translation Using Monolingual Corpora Only" submitted by ICLR 2018 is a representative technical idea. It uses non-aligned bilingual training corpus. The training machine translation system was assembled and achieved good results. This technical idea is essentially similar to CycleGAN. I believe that this unsupervised model will have a lot of follow-up research in 2018. Secondly, it is a promising direction to enhance learning and how GAN and other popular technologies in the past two years have combined with NLP and really played a role. In the past year, this aspect of exploration has made progress and made some progress, but it is obvious that this The road has not yet passed, and this piece is worth continuing to explore. Thirdly, the Attention Attention Mechanism is further widely used and introduces more variants, such as Self Attention and Hierarchy Attention. The technical idea of ​​"Attention is all you need" from Google's new machine translation can clearly understand this trend. In addition, how to combine some prior knowledge or linguistic domain knowledge and neural network is a popular research trend, such as the explicit introduction of sentence syntactic structure and other information into the Sequence to Sequence framework. In addition, the interpretability of neural networks is also a research hotspot, but this is not only limited to the NLP field, but also a research trend that is of great concern throughout the depth learning field.
This paper selects a number of AI technology fields with high attention to explain the important technological progress in this field in the past year. Due to the author's ability and the limitations of the main areas of concern, it is inevitable that there will be a lot of important technical progress in many aspects. For example, the rapid development of AI chip technology represented by Google's push of TPU allows the machine to automatically learn to design neural network structure as the representative of "learning everything" and to solve the problem of neural network black box problem and other important areas of progress. Failure to mention or expand in the text is a very noteworthy development direction of AI technology.
In the past year, major technological advances have taken place in many areas of AI, and many fields have been slow to move forward. However, the author of this article believes that AI will produce technological advances that subvert the current human imagination in many fields in the coming years. We look forward to the early arrival of this day!
Printed Circuit Board Membrane Switch
When the circuit used in the Membrane Switch design is a printed circuit board (PCB) you`ll see the unit called a PCB membrane switch.
While Telamco is a PCB membrane switch manufacturer we also provide other circuit options such as screened silver and flexible printed circuits. Each circuit option provides different benefits, which we can help walk you through during your decision process.
Printed Circuit Boards benefits:
High circuit density
Multi-circuit layers
Simplify design
Reduce space
Rigid
Can solder electronic components
Potential cost savings
PCB switches provide many valuable options for product designs and functionality. We`ll help you create quality membrane switches to meet the needs of your product. Quality design and function are important.
Printed Circuit Board Membrane Switch,Manipulation Membrane Switch,Therapeutic Apparatus Membrane Switch,3M Membrane Switch
Dongguan Nanhuang Industry Co., Ltd , https://www.soushine-nanhuang.com