In my recent research, the author found a very good paper on the dialogue system, "A Survey on Dialogue Systems: Recent Advances and New Frontiers", the paper from the Jingdong data team, the paper cited 124 papers, is a A comprehensive introduction to the dialogue system article can be described as sincerity, and today we will focus on the interpretation of readers.
Foreword
Having a virtual assistant or a chat partner system with enough intelligence seems illusory and may only exist for a long time in science fiction movies. In recent years, human-machine dialogue has attracted more and more researchers' attention because of its potential potential and attractive business value.
With the development of big data and deep learning technologies, creating an automated human-machine dialogue system as our personal assistant or chat partner will no longer be an illusion.
At present, the dialogue system has attracted more and more attention in various fields. The continuous improvement of deep learning technology has greatly promoted the development of the dialogue system. For dialog systems, deep learning techniques can use a large amount of data to learn feature representation and reply generation strategies, which require only a small amount of manual manipulation.
Nowadays, we can easily access the “big data†of conversations on the web, we may be able to learn how to reply, and how to respond to almost any input, which will greatly allow us to build data-driven, between humans and computers. An open dialogue system.
On the other hand, deep learning techniques have proven to be effective, capture complex patterns in big data, and have a large number of research areas, such as computer vision, natural language processing, and recommendation systems. In this article, the authors provide an overview of these recent developments on the dialogue system from different perspectives and discuss some possible research directions.
Specifically, the dialogue system can be roughly divided into two types:
(1) Task-oriented dialogue system and
(2) Non-task-oriented dialogue systems (also known as chat bots).
Task-oriented systems are designed to help users complete specific tasks, such as helping users find items, booking hotel restaurants, and more.
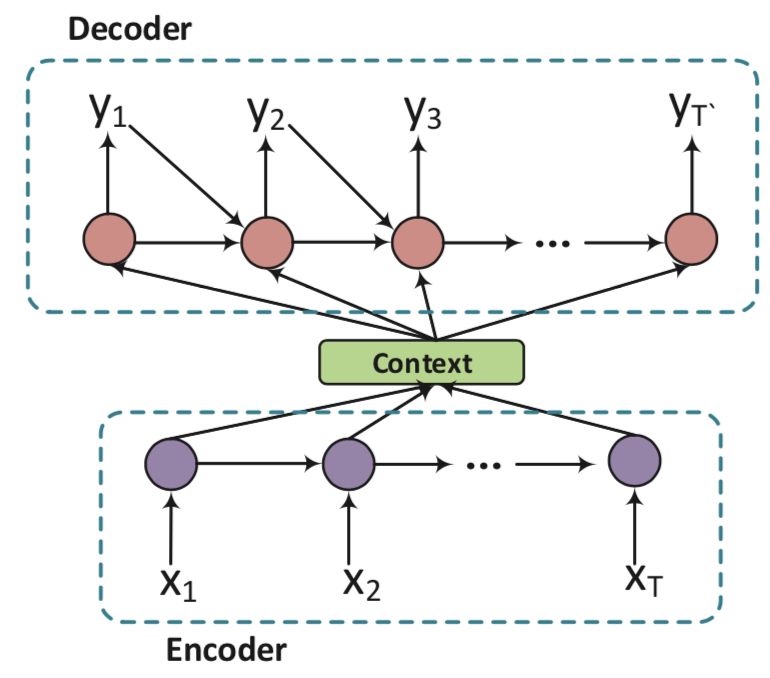
The widely used approach to task-oriented systems is to treat the dialog response as a pipeline, as shown in the following figure:
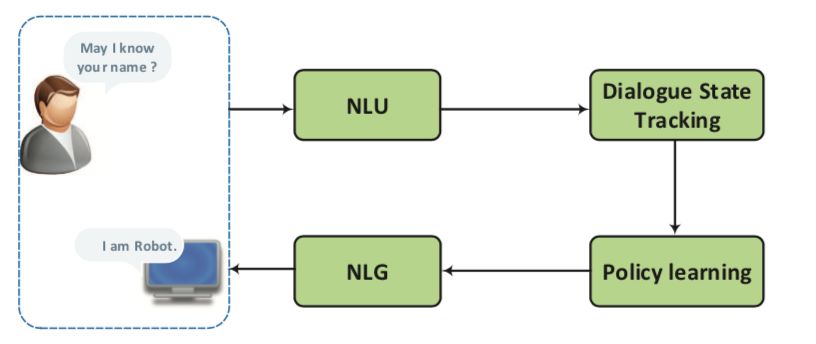
The system first understands the information conveyed by human beings as an internal state, then adopts a series of corresponding behaviors according to the strategy of the state of dialogue, and finally transforms the actions into expressions of natural language.
Although language understanding is handled through statistical models, most deployed dialog systems still use manual features or manually crafted rules for state and action space representation, intent detection, and slot filling.
The non-mission-oriented dialogue system interacts with humans to provide reasonable responses and recreational functions, usually focusing on open areas to talk to people. While non-task-oriented systems seem to be chatting, it works in many real-world applications.
The data shows that in the online shopping scene, nearly 80% of the words are chat information, and the way to deal with these problems is closely related to the user experience.
In general, for non-mission-oriented dialogue systems, there are two main methods currently used:
(1) The generation method, such as sequence-to-sequence model (seq2seq), generates appropriate responses during the dialogue process. The generation-type chatbot is currently a hotspot in the research community. Unlike the retrieval-type chat bot, it can generate a kind of A new response, so it's relatively more flexible, but it also has its own shortcomings, such as sometimes grammatical errors, or generate some meaningless responses;
(2) Based on the retrieval method, a search is performed from a previously defined index, and learning to select a reply from the current conversation. The disadvantage of the retrieval method is that it relies too much on the quality of the data. If the quality of the selected data is not good, it is very likely that it will be abandoned.

In recent years, the rapid development of big data and deep learning technology has greatly promoted the development of task-oriented and non-oriented dialogue systems.
In this paper, the author's goal is to (1) outline the dialogue system, especially the recent progress in deep learning; and (2) discuss possible research directions.
Task-oriented system
A task-oriented dialogue system is an important branch of the dialogue system. In this section, the authors summarize the pipeline approach and end-to-end approach to task-oriented dialog systems.
Pipeline method
The typical structure of a task-oriented dialog system has been shown in the previous figure, which consists of four key components:
1) Natural Language Understanding (NLU): It parses user input into predefined semantic slots. If there is an utterance, natural language understanding maps it to a semantic slot. The slots are pre-defined according to different scenarios.

The figure above shows an example of a natural language representation where "New York" is the location specified as the slot value and specifies the domain and intent, respectively. Typically, there are two types of representations. One is the discourse level category, such as the user's intent and discourse category. The other is word-level information extraction, such as named entity recognition and slot filling. Dialogue intent detection is to detect the user's intention. It divides the discourse into a predefined intent.
2) Dialogue State Tracker (DST). Conversational state tracking is a core component of ensuring the robustness of a conversational system. It estimates the user's goals in each round of the conversation, manages the input and conversation history for each round, and outputs the current conversation state. This typical state structure is often referred to as a slot fill or semantic framework. Traditional methods have been widely used in most commercial implementations, often using manual rules to select the most likely output. However, these rule-based systems are prone to frequent errors because the most likely outcomes are not always ideal.
A recent approach to deep learning is to use a sliding window to output a sequence of probability distributions of any number of possible values. Although it is trained in one area, it can be easily transferred to new areas. The models used here are multi-domain RNN dialog state tracking models and Neural Belief Tracker (NBT).
3) Dialogue policy learning. Based on the state of the status tracker, policy learning is to generate the next available system operation. Both supervised learning and intensive learning can be used to optimize policy learning. Supervised learning is performed on the behavior generated by the rules. In the online shopping scenario, if the conversation status is “recommendedâ€, the “recommended†operation is triggered and the system will retrieve the product from the product database. The introduction of reinforcement learning methods can further train the dialogue strategy to guide the system to develop the final strategy. In practical experiments, the effect of reinforcement learning methods outweighs rules-based and supervisory methods.
4) Natural Language Generation (NLG). It maps the selection action and generates a reply.
A good generator usually depends on several factors: appropriateness, fluency, readability, and variability. The traditional NLG method is usually to execute a sentence plan. It maps the input semantic symbols to an intermediary form that represents the utterance, such as a tree or template structure, and then transforms the intermediate structure into a final response through a surface implementation. The more mature method of deep learning is based on the LSTM encoder-decoder form, which combines problem information, semantic slot values ​​and dialog behavior types to generate correct answers. At the same time, the attention mechanism is utilized to process the key information about the current decoding state of the decoder, and different responses are generated according to different behavior types.
2. End-to-end method
Although traditional task-oriented dialogue systems have many specific fields of handcrafting, they are difficult to adapt to new fields. In recent years, with the development of end-to-end neural generation models, end-to-end dialogue systems have been built. The trainable framework at the end. It is worth noting that when we introduce a non-task-oriented dialog system, more details about the neurogenic model will be discussed. Unlike traditional pipeline models, the end-to-end model uses a module and interacts with a structured external database.
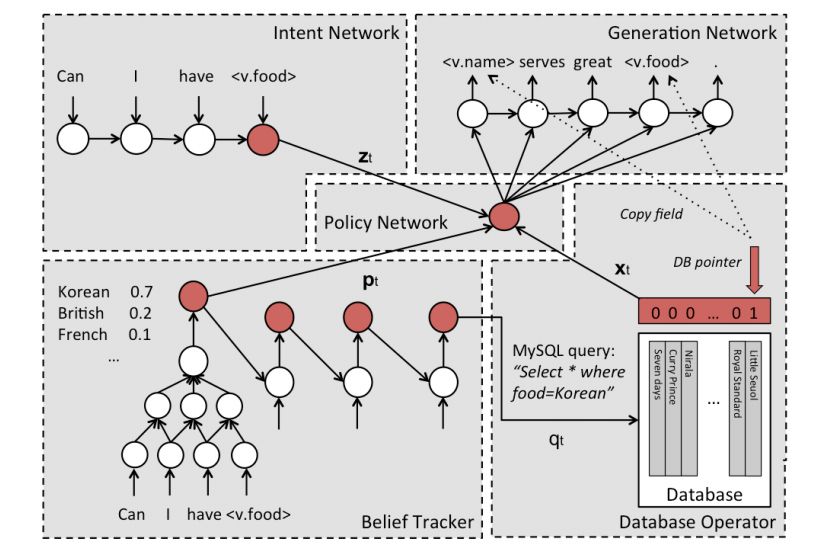
The model in the above figure is a network-based end-to-end trainable task-oriented dialogue system. The learning of the dialogue system is used as a mapping problem from learning history to system response, and the encoder-decoder model is used to train. However, the system is trained in a supervised manner – not only does it require a large amount of training data, but it may not be able to find a good strategy due to the lack of further exploration of the training data dialog controls.
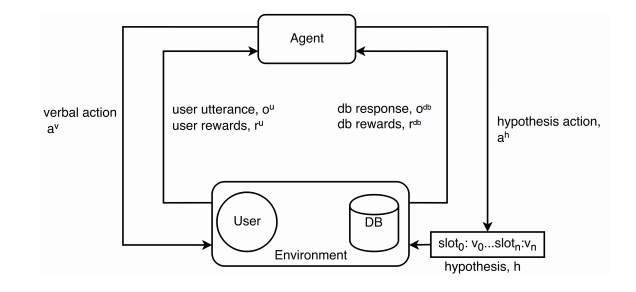
With the deepening of reinforcement learning research, the model of the above figure first proposes an end-to-end reinforcement learning method, which jointly trains conversation state tracking and dialogue strategy learning in dialogue management, thereby more effectively optimizing the system's actions. .
Non-mission oriented system
Unlike task-oriented dialogue systems, its goal is to accomplish specific tasks for users, while non-task-oriented conversation systems (also known as chat bots) focus on talking to people in open areas. In general, chat bots are implemented by either a generation method or a retrieval-based method.
Generating models can generate more appropriate responses, which may never appear in the corpus, while search-based models have the advantage of ample information and responsiveness.
1. Neural Generative Models
The successful application of deep learning in machine translation, namely neural machine translation, has spurred people's enthusiasm for neurogenic dialogue research. At present, the popular research topics of neurogenic models are as follows.
1.1 Sequence-to-Sequence Models
Given an input sequence containing words)
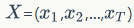
And the target sequence of length T (response)
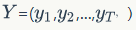
The model maximizes the conditional probability of Y under X:
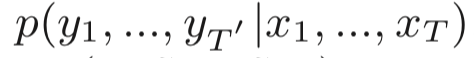
Specifically, the Seq2Seq model is in the encoder-decoder structure, and the following figure is an illustration of this structure:
The encoder reads X word by word and represents it as a context vector c by a recurrent neural network (RNN), which then uses c as an input to estimate the probability of Y generation.
(1) The Encoder Encoder process is very simple, using RNN (usually LSTM) for semantic vector generation:
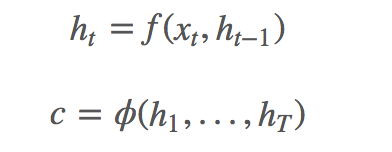
Where f is a nonlinear function, such as LSTM, GRU, 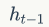
Is the last hidden node output, 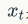 It is the input of the current moment. The vector c is usually the last hidden node (h, Hidden state) in the RNN, or a weighted sum of multiple hidden nodes.
It is the input of the current moment. The vector c is usually the last hidden node (h, Hidden state) in the RNN, or a weighted sum of multiple hidden nodes.
(2) The decoder process of the Decoder model is to use another RNN to pass the current hidden state. 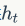 To predict the current output symbol
To predict the current output symbol  ,here with Both are related to their previous hidden state and output. The objective function of Seq2Seq is defined as:
,here with Both are related to their previous hidden state and output. The objective function of Seq2Seq is defined as:
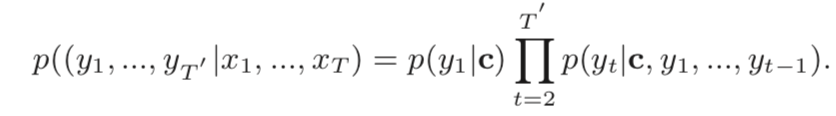
2. Dialogue Context
Considering the contextual information of the conversation is the key to building a dialogue system that keeps the conversation coherent and enhances the user experience. Use a hierarchical RNN model to capture the meaning of individual sentences and then integrate them into a complete conversation.
At the same time, the hierarchical structure is extended by the word-level and sentence-level attention methods.
Test proved:
(1) The performance of hierarchical RNNs is usually better than that of non-hierarchical RNNs;
(2) After considering context-related information, neural networks tend to produce longer, more meaningful, and versatile responses.
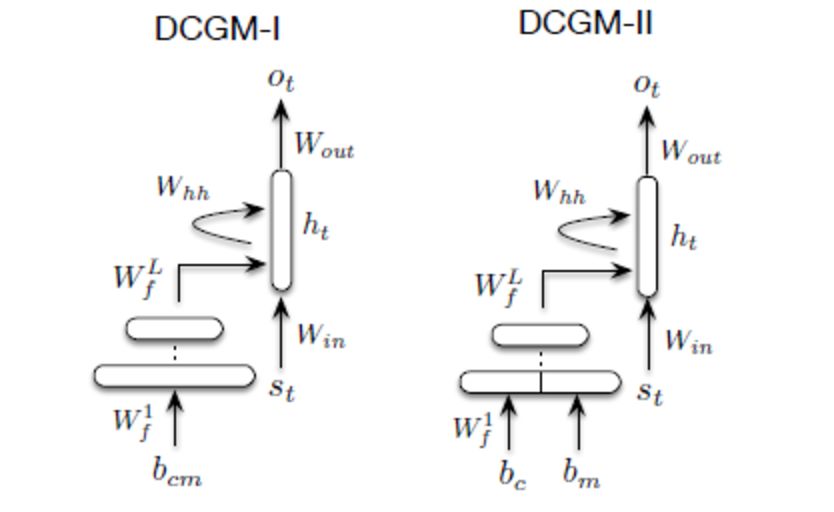
In the above diagram, the author solves this problem of context-sensitive response generation by representing or embedding words and phrases in a continuous representation of the entire conversation history (including current information).
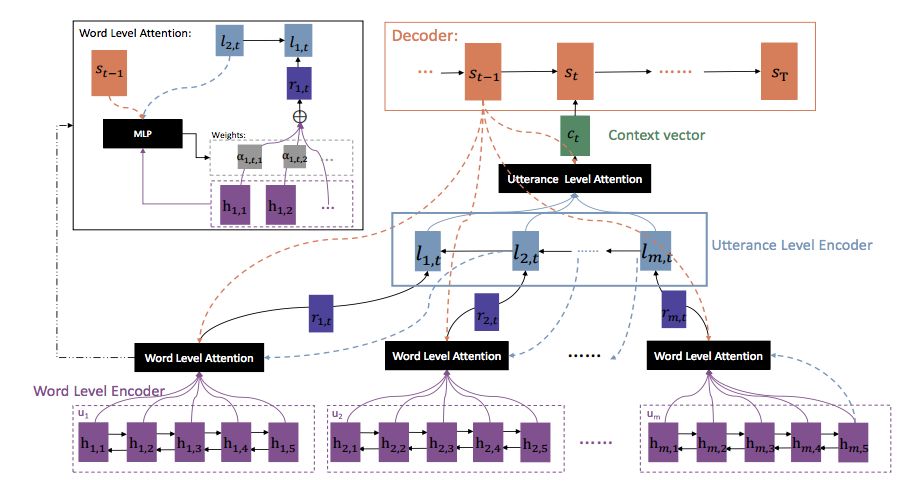
In the structure of the above figure, the author introduces two levels of Attention mechanism, which allows the model to automatically learn the importance information of words and sentences, so as to generate a new round of dialogue.
In the sentence-level information, the author is reverse-learning, that is, the information of the next sentence can be more included in the information of the previous sentence, so in general, the learning of the dialogue is to reverse the content of each round of dialogue. .
1.3 Response Diversity (Response Diversity)
A challenging problem in the current Seq2Seq dialog system is that they tend to produce insignificant or ambiguous, ordinary, almost meaningless responses that often involve something like "I don't know" ", "I am OK" is a meaningless reply.
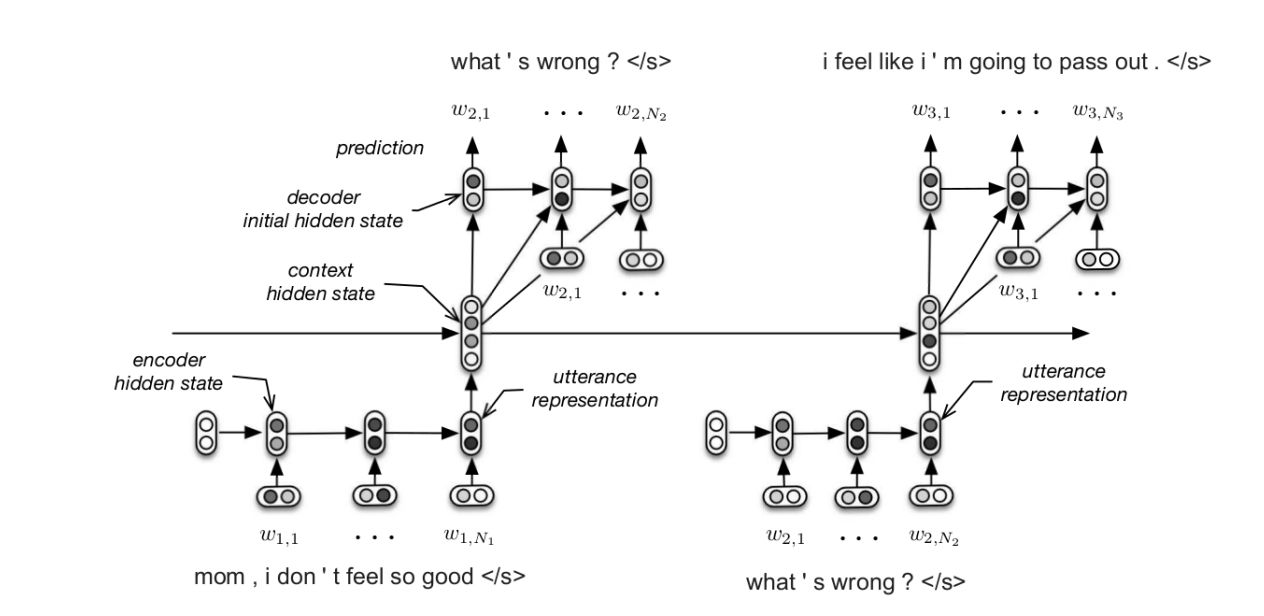
A very effective way to solve this type of problem is to find and set a better objective function. In addition, one way to solve such problems is to increase the complexity of the model. The following figure, "Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models," uses the latent variable to solve the problem of meaningless reply.
1.4 Topic and Personality Defining the intrinsic nature of dialogue is another way to increase the diversity of conversations and ensure consistency. Among different attributes, the theme and personality are widely studied.
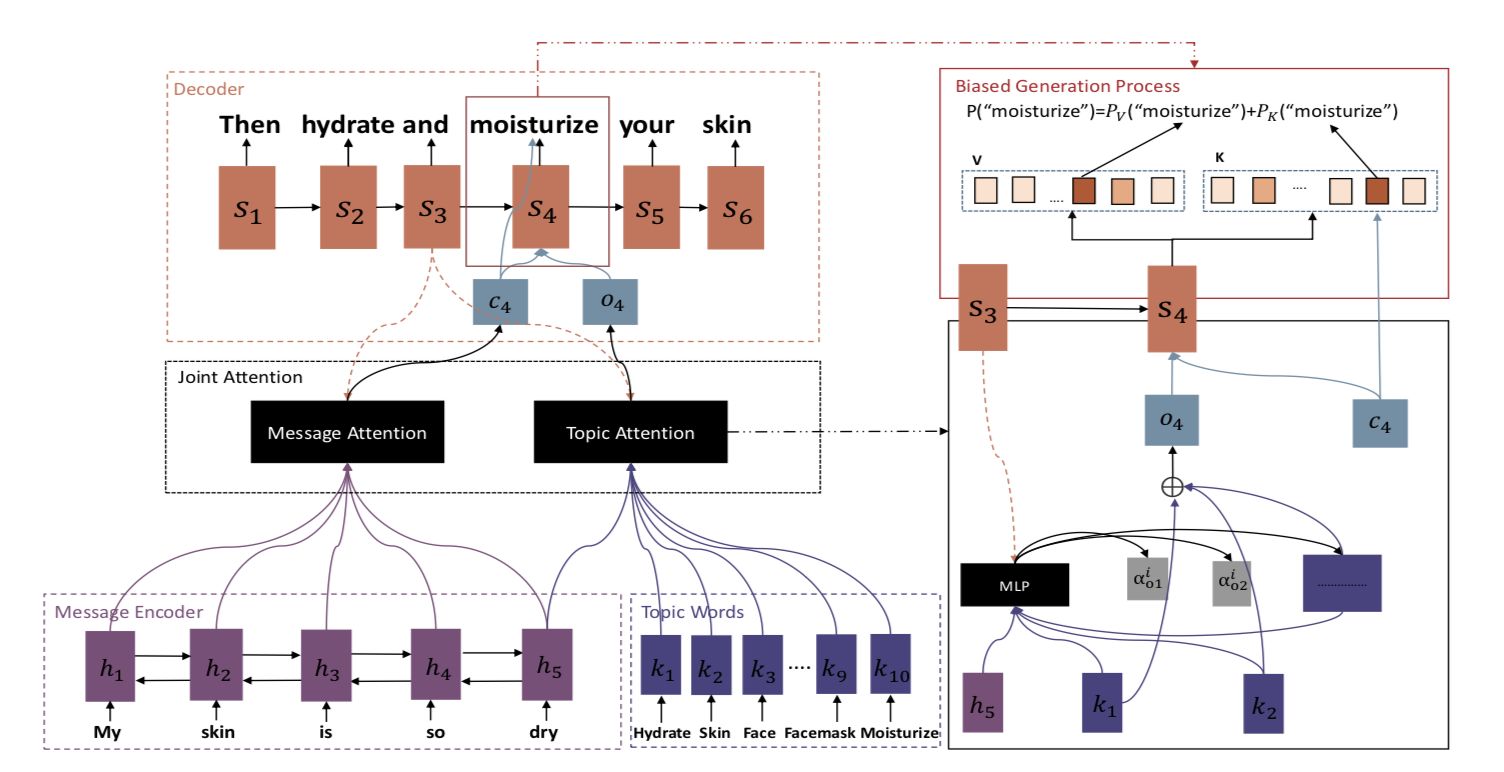
In the model below, the authors note that people often associate their conversations with topic-related concepts and respond to them based on these concepts. They use the Twitter LDA model to get the input topic, input the topic information and input representation into a joint attention module, and generate a topic-related response.
The model in the figure below proposes a two-stage training method that initializes the model using large-scale data and then fine-tunes the model to generate a personalized response.
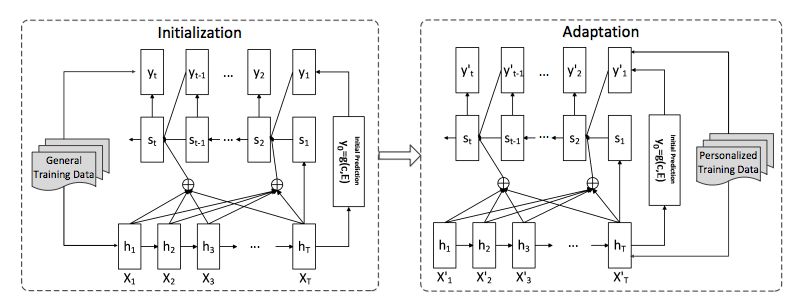
1.5 External Knowledge Base
An important difference between the human dialogue and the dialogue system is whether it is integrated with reality. Combining an external knowledge base (KB) is a promising way to bridge the gap between background knowledge, the gap between the dialogue system and people.
The Memory Network is a classic way to handle problems with a knowledge base. Therefore, it is very straightforward to use in dialog generation. Practical research has shown that the proposed model can generate natural and correct answers to the problem by referring to facts in the knowledge base.
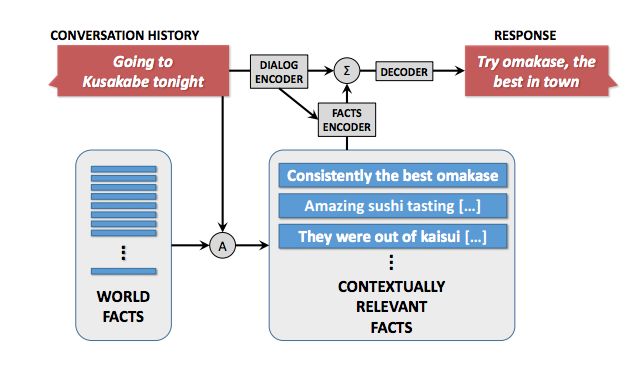
The above picture is a fully data-driven, conversational model with knowledge proposed by the author. The World Facts is a collection that collects some authoritatively certified sentences or inaccurate sentences as a knowledge base.
When you specify an input S and history, you need to retrieve the relevant facts in the Fact collection. The IR engine used here searches and then Fact Encoder performs the fact injection.
The model above proposes a new, data-driven, knowledge-based neural dialogue model that produces more content without slots. The authors summarize the widely used SEQ2SEQ method by responding to session history and external "facts".
1.6 Evaluation The quality of the evaluation response is an important aspect of the dialogue system. The task-oriented dialogue system can be evaluated based on manually generated supervisory signals, such as task completion tests or user satisfaction ratings. However, due to the diversity of high responses, the quality of the response generated by the automated assessment of non-mission-oriented dialog systems remains an open question. The current methods are as follows:
1) Calculate the BLEU value, that is, directly calculate the word overlap, ground truth, and the response you generated. Since there may be multiple responses in a single sentence, in some ways, BLEU may not be suitable for conversational evaluation.
2) Calculate the distance of embedding. This method is divided into three cases: direct addition and averaging, first taking absolute value and then averaging and greedy matching.
3) Measuring diversity depends mainly on the number of distinct-ngrams and the size of entropy values. 4) Perform a Turing test and evaluate the response generation with a recricin discriminator.
Search based method
A search based method selects a reply from the candidate responses. The key to the retrieval method is message-response matching, which must overcome the semantic gap between messages and responses.
2.1 Single-round replies Matching Early research on retrieving chat bots focused on responding to single-round conversations, with only messages used to select an appropriate response. The current relatively new method is as follows, using the deep convolutional neural network architecture to improve the model, learning the representation of messages and responses, or directly learning the interaction representation of two sentences, and then using the multi-layer perceptron to calculate the matching score.
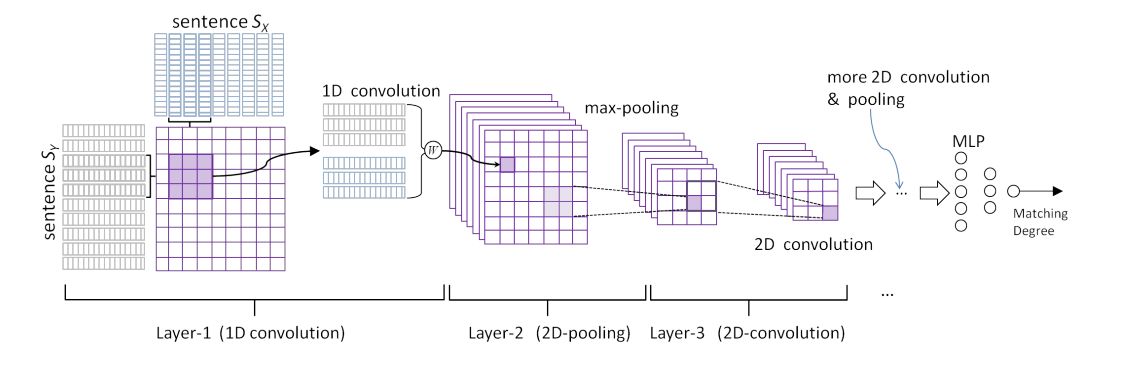
2.2 Multiple rounds of match matching
In recent years, multi-round conversations based on retrieval have attracted more and more attention. In multiple rounds of answer selection, the current message and the previous utterance are taken as input.
The model selects a natural, context-sensitive response. It is important to find important information in the previous discourse and properly imitate the relationship of the discourse to ensure continuity of conversation.
The difficulty of multiple rounds of dialogue is not only to consider the current issues, but also to consider the dialogues of the previous rounds. There are two main difficulties in multi-round dialogue:
1. How to identify the key information of the context (keywords, key phrases or key sentences);
2. How to simulate the relationship between multiple rounds of dialogue in the context.
Defects of existing search models: Important information is easily lost in context because they first represent the entire context as a vector and then match the context vector to the response sentence vector. The method of the following figure encodes the context (the connection of all previous utterances and the current message) and the candidate response into the context vector and the reply vector respectively through the structure of the RNN/LSTM, and then calculates the matching score based on the two vectors.
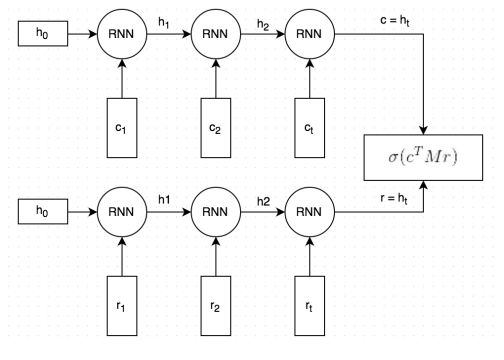
At present, the chat about the retrieval model is still in a single round of dialogue. The following paper proposes a multi-round conversation chat based on retrieval. The paper proposes a multi-round chat structure based on retrieval, which further improves the use of discourse relations and context information by matching the statements in the context with the different levels of the convolutional neural network and then in a time series through a recursive neural network. These vectors are stacked in order to establish the relationship between the conversations.
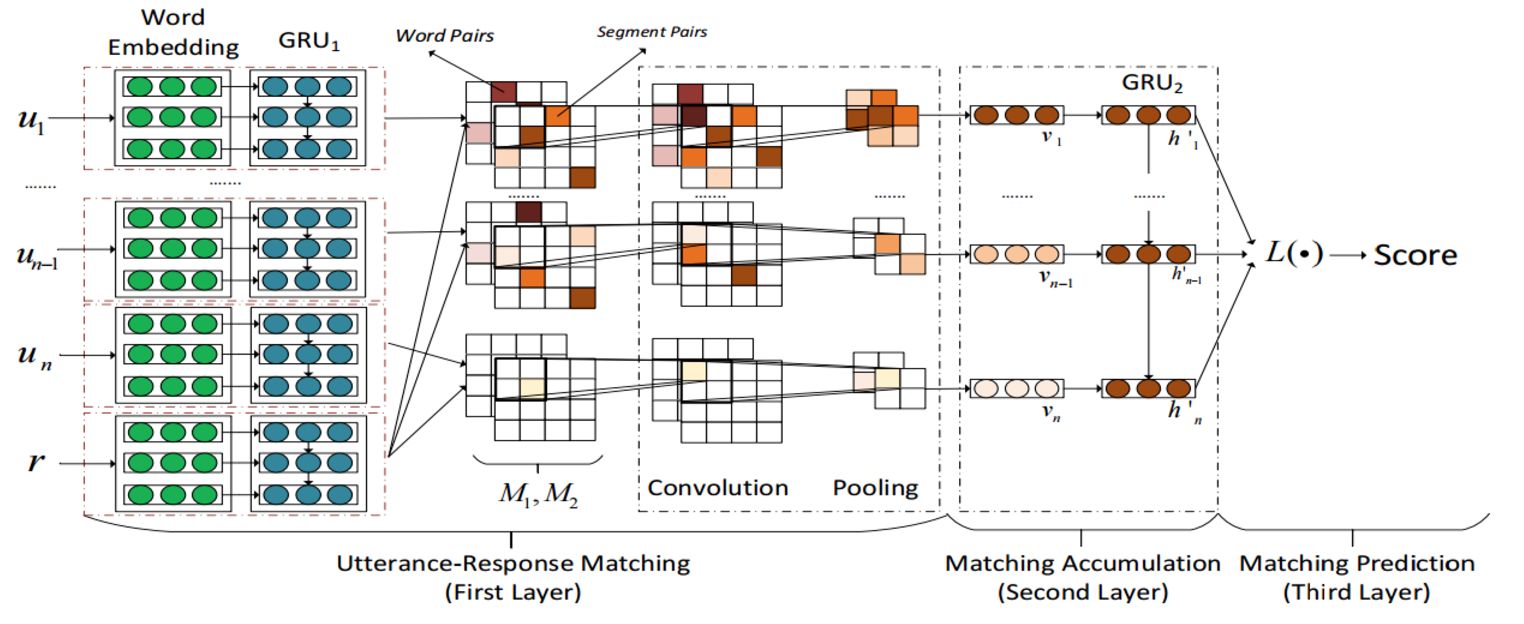
Mixed method
Combining the generation and retrieval methods can significantly improve system performance. Retrieval-based systems usually give precise but blunt answers, while generation-based systems tend to give smooth but meaningless answers.
In the integrated model, the extracted candidate is entered into the RNN-based reply generator along with the original message. This approach combines the advantages of a search and generation model, which has great performance advantages.
future development
Deep learning has become a basic technology in the dialogue system. Researchers apply neural networks to different components of traditional task-oriented dialogue systems, including natural language understanding, natural language generation, and conversation state tracking. In recent years, the end-to-end framework has become popular not only in non-task-oriented chat conversation systems, but also in task-oriented conversation systems.
Deep learning can make use of a large amount of data, thus blurring the boundary between a task-oriented dialogue system and a non-mission-oriented dialogue system. It is worth noting that the current end-to-end model is still far from perfect. Despite these achievements, these issues remain challenging. Next, we will discuss some possible research directions.
Adapt quickly. Although end-to-end models are increasingly attracting the attention of researchers, we still need to rely on traditional pipeline methods in practical engineering, especially in some new areas, the collection of dialogue data in specific areas and the construction of dialogue systems. More difficult. The future trend is that conversation models have the ability to actively learn from interactions with people.
Deep understanding. At this stage, the neural network-based dialogue system relies heavily on a large amount of labeled data, a structured knowledge base, and dialog corpus data. In a sense, the response is still lacking in diversity, sometimes not so much, so the dialogue system must be able to understand the language and the real world more effectively.
privacy protection. The currently widely used dialogue system serves more and more people. It is important to note the fact that we are using the same dialogue assistant. Through the learning ability of interaction, understanding and reasoning, the dialogue assistant can inadvertently store some sensitive information. Therefore, it is very important to protect the privacy of users when building a better dialogue mechanism.
Steel Cord For Conveyor Belts
Steel cord conveyor belts are highly wear-resistant and used principally for long-haul conveying, heavy loads and physically demanding applications. They are especially suitable for high-mass or high-volume flows and for abrasive materials.
Steel cord Conveyor Belt Construction
The steel cord belt provides superior impact resistance, with the number and size being selected to meet the desired operating tension and application needs. The insulation gum is specifically designed to encapsulate each steel cord filament to reduce internal friction while providing enhanced adhesion to the cover rubbers. Top and bottom covers provide maximum protection to the steel cord. The cover compounds are specifically designed to meet the demands of the application and are available in a wide variety of rubber types and gauges.
Steel Cord,Steel Cord Wire,Steel Wire Cord,Conveyor Belt Steel Cord
ROYAL RANGE INTERNATIONAL TRADING CO., LTD , https://www.royalrangelgs.com