Face recognition technology not only attracted a large number of R&D investment from domestic and foreign Internet giants such as Google, Facebook, Ali, Tencent, Baidu, etc., but also spawned a large wave of star startups such as Face++, Shangtang Technology, Linkface, Zhongke Yunconi and Yitu. In the direction of video surveillance, criminal investigation, Internet financial identity verification, self-service clearance system, etc., many successful application cases have been created. This paper attempts to sort out the development of face recognition technology, and gives some practical design according to the author's practice in related fields, expecting to benefit the interested readers.
Overview
In layman's terms, any machine learning problem can be equivalent to a problem finding a suitable transformation function. For example, speech recognition is to find a suitable transformation function to transform the input one-dimensional time-series speech signal into the semantic space; and the Go artificial intelligence AlphaGo, which has recently attracted the attention of the whole people, transforms the input two-dimensional layout image into the decision space. Determine the optimal way to move in the next step; correspondingly, face recognition is also to find a suitable transformation function, transform the input two-dimensional face image into the feature space, so as to uniquely determine the identity of the corresponding person.
People have always thought that Go is much more difficult than face recognition. Therefore, when AlphaGo easily defeated the world champion Li Shizhen and Ke Jie in the absolute advantage, people were even more impressed by the power of artificial intelligence. In fact, this conclusion is just a misunderstanding of people based on "common sense", because from the experience of most people, even after rigorous training, the chances of defeating the world champion of Go are negligible; on the contrary, most ordinary people, even The task of face recognition can be easily accomplished without strict training. However, we may wish to carefully analyze the difficulty between the two: in the "eyes" of the computer, the chess board of Go is nothing more than a 19x19 matrix. The possible values ​​of each element of the matrix come from a triple. {0,1,2}, representing no children, white and black, respectively, so the possible value of the input vector is 3361; for face recognition, taking a 512x512 input image as an example, it is in the computer "In the eye" is a 512x512x3-dimensional matrix. Each element of the matrix may have a value range of 0~255, so the possible value of the input vector is 256786432. Although Go AI and face recognition both seek a suitable transformation function f, the complexity of the latter input space is obviously much larger than the former.
For an ideal transformation function f, in order to achieve the optimal classification effect, in the transformed feature space, we hope that the intraclass difference of the same kind of sample is as small as possible, and the interclass difference of different types of samples is as large as possible. However, the ideal is full, but the reality is bone. Due to the influence of lighting, expression, occlusion, posture and other factors (Figure 1), the gap between different people is often smaller than that between the same people, as shown in Figure 2. The history of the development of face recognition algorithms is a history of struggles with these identification influence factors.

Figure 1 Influencing factors of face recognition
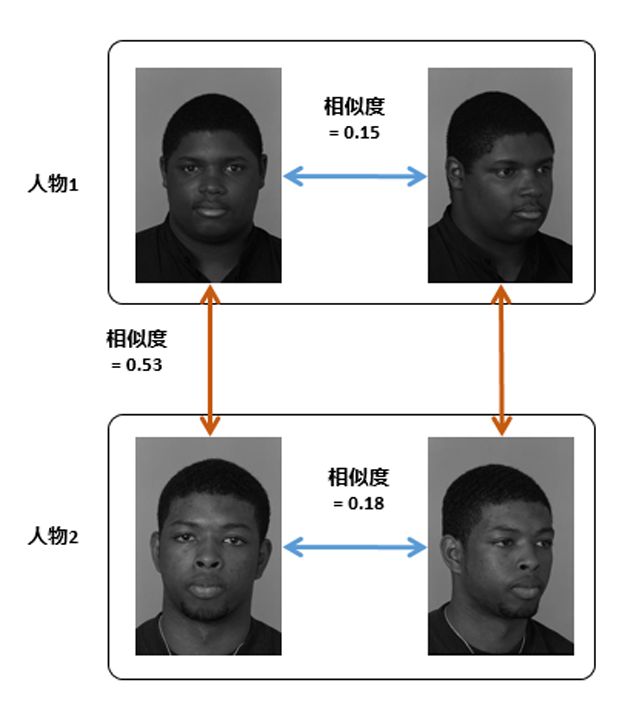
Figure 2 posture causes different people to be more similar than their peers
Face recognition technology development
As early as the 1950s, cognitive scientists began to study face recognition. In the 1960s, face recognition engineering application research was officially launched. At that time, the method mainly utilized the geometric structure of the face and identified it by analyzing the feature points of the face organs and the topological relationship between them. This method is simple and intuitive, but once the face posture and expression change, the accuracy is seriously degraded.
In 1991, the famous "feature face" method [1] introduced principal component analysis and statistical feature technology into face recognition for the first time, and made great progress in practical effects. This idea has been further developed in subsequent research. For example, Belhumer successfully applied the Fisher discriminant criterion to face classification, and proposed the Fisherface method based on linear discriminant analysis [2].
In the first decade of the 21st century, with the development of machine learning theory, scholars have successively explored face recognition based on genetic algorithm, Support Vector Machine (SVM), boosting, manifold learning and kernel method. From 2009 to 2012, Sparse Representation [3] became a research hotspot at that time because of its beautiful theory and robustness to occlusion factors.
At the same time, the industry has basically reached a consensus: feature extraction and subspace methods based on artificially designed local descriptors for feature selection can achieve the best recognition results. The Gabor [4] and LBP [5] feature descriptors are the two most successful artificially designed local descriptors in the field of face recognition. During this period, the targeted processing of various face recognition influence factors is also the research hotspot of that stage, such as face illumination normalization, face pose correction, face super resolution and occlusion processing. Also at this stage, the researchers' attention began to shift from face recognition in restricted scenes to face recognition in unconstrained environments. The LFW face recognition open competition became popular in this context. At the time, the best recognition system achieved more than 99% recognition accuracy on the limited FRGC test set, but the highest accuracy on the LFW was only about 80%. It seems quite far from practical.
In 2013, MSRA researchers first tried large training data of 100,000 scale and obtained 95.17% accuracy on LFW based on high-dimensional LBP features and Joint Bayesian method [6]. This result indicates that large training data sets are important for effectively improving face recognition in unconstrained environments. However, all of these classic methods are difficult to handle training scenarios for large data sets.
Around 2014, with the development of big data and deep learning, neural networks have attracted much attention, and have obtained far more results than classical methods in image classification, handwriting recognition, and speech recognition. Sun Yi et al. of the Chinese University of Hong Kong proposed the application of convolutional neural networks to face recognition [7]. Using 200,000 training data, the first time in LFW, the recognition accuracy exceeded the human level. This is the development of face recognition. A milestone in history. Since then, researchers have continued to improve the network structure, while expanding the size of the training sample, pushing the recognition accuracy on the LFW to more than 99.5%. As shown in Table 1, we give some classic methods in the development of face recognition and its accuracy on LFW. A basic trend is that the training data is getting larger and larger, and the recognition accuracy is getting higher and higher. If the reader is interested in reading the development history of face recognition in more detail, you can refer to the literature [8] [9].
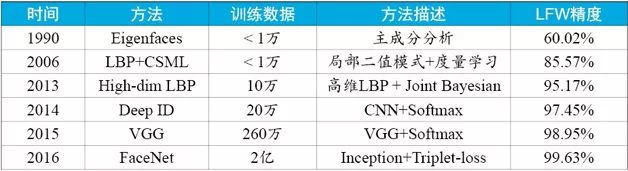
Table 1 Classic method of face recognition and its accuracy comparison on LFW
Technical solutions
To achieve high-precision face recognition in practice, it is necessary to specifically design the challenges of face recognition such as illumination, gesture, and occlusion. For example, for lighting and attitude factors, either collect training samples to ensure that each individual covers enough illumination and attitude changes, or design effective pre-processing methods to compensate for facial identity information from lighting and gestures. Variety. Figure 3 shows some of the author's research results in related fields [10][11].

Table 2 Normal face recognition training set
Table 2 shows the training data sets used in this paper. The first three are the current most popular public training data sets, and the last one is the private business data set. Table 3 gives two data sets and test protocols for performance verification, of which LFW is currently the most popular unrestricted face recognition open competition. We noticed that most training sets have large noise, and if it is not cleaned, the training will be difficult to converge. This paper presents a fast and reliable data cleaning method, as shown in Table 4.

Table 3 Test sets used in this article

Table 4 A fast and reliable training data cleaning method
Figure 4 shows a set of effective face recognition technology solutions, including multi-patch partitioning, CNN feature extraction, multi-task learning/multi-loss fusion, and feature fusion module.
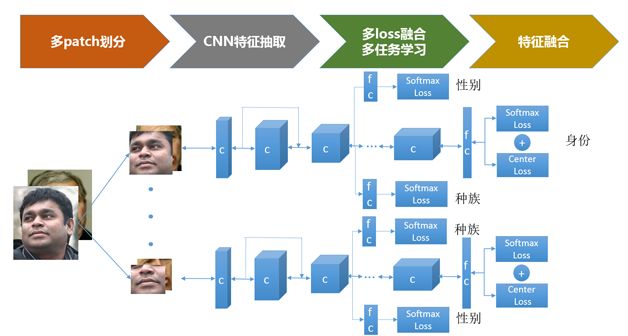
Figure 4 face recognition technology solution
The multi-patch division mainly uses the complementary information between different patches of the face to enhance the recognition performance. In particular, the fusion between multiple patches can effectively improve the recognition performance under occlusion. Currently, more than 99.50% of the results in the LFW review are mostly derived from multiple patch fusions.
The well-proven facial feature extraction convolutional neural network includes: Deep-ID series, VGG-Net, ResNet, Google Inception structure. Readers can choose the right network for their accuracy and efficiency needs. This article uses 19 layers of resnet as an example.
Multitasking is mainly to use other relevant information to enhance face recognition performance. This article takes gender and ethnicity recognition as examples. These two attributes are strongly related to the identity of specific people, while other attributes such as expression and age do not. We extracted branches in the middle layer of resnet for multi-task learning of race and gender, so that the first few layers of CNN network are equivalent to high-level semantic information with racial and gender discriminative power. We further learn identity in the later layers of CNN network. Refine the authentication information. At the same time, the gender and ethnicity of the sample in the training set can be obtained by majority voting through a baseline classifier.
The multi-loss fusion mainly uses the complementary characteristics between differentloss to learn the appropriate face feature vector, so that the intra-class difference is as small as possible, and the inter-class difference is as large as possible. The current concentrated loss in the field of face recognition includes: pair-wise loss, triplet loss, softmax loss, center loss, and the like. Among them, triplet loss directly defines the optimization goal of increasing the gap between classes within the class, but in the concrete engineering practice, it has more tricks and is not easy to grasp. The recently proposed center loss, combined with softmax loss, can better measure the intra-class and inter-class differences in the feature space, and the training configuration is also convenient, so it is widely used.
Models obtained through multiple patch training will generate multiple feature vectors. How to fuse multiple feature vectors for final identification is also an important technical issue. The more common schemes include: feature vector splicing, fractional weighted fusion, and decision-level fusion (such as voting).
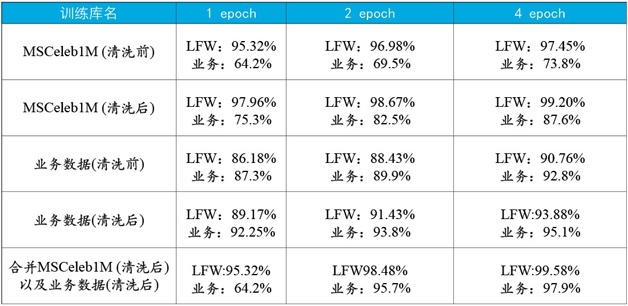
Table 5 Performance comparison of identification models before and after data cleaning
Table 5 gives the performance comparison results of the training data on the test set before and after cleaning. Based on this, the following conclusions can be drawn:
The cleaning of the data can not only speed up the model training, but also effectively improve the recognition accuracy;
The model trained on the Western-based training set MSCeleb1M achieves perfect generalization performance on the LFW, which is also dominated by Westerners. However, the generalization performance of the business test set based on the Orientals is better. Big decline
The model trained in the business training set based on the Orientals has a very good performance on the Oriental-based business test set, but there is a certain gap in the Western-based test set LFW relative to MSCeleb1M;
Combining the business training set with MSFelb1M, the trained model has near-perfect performance on both LFW and business data. Among them, the model based on three patch fusions has a recognition accuracy of 99.58% on LFW.
From this, we can know that in order to achieve the highest possible practical recognition performance, we should try to train with the same training data as the use environment. The same conclusions appear in the paper [12].
In fact, a complete face recognition utility system, in addition to the above-mentioned recognition algorithm, should also include face detection, face key point positioning, face alignment and other modules, in some applications with higher security level requirements, To prevent spoofing attacks on the recognition system, such as photos, video playback, 3D printing models, etc., it is also necessary to introduce a living body detection module; in order to obtain an optimal recognition effect in the video input, it is also necessary to introduce an image quality evaluation module to select the most suitable video frame. Identify to minimize the effects of uneven illumination, large pose, low resolution, and motion blur on recognition. In addition, many researchers and companies have tried to circumvent the impact of these factors in a proactive manner: the introduction of infrared / 3D cameras. A typical practical face recognition scheme is shown in Figure 5.
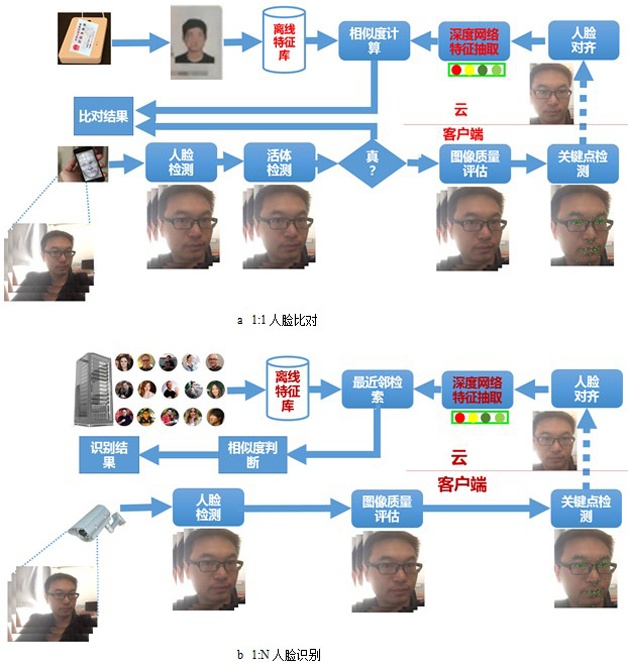
Figure 5 Flow chart of the practical face recognition scheme
to sum up
This paper briefly summarizes the development history of face recognition technology and gives a reference for practical design. Although face recognition technology has achieved more than 99% accuracy in the LFW open competition, there is still a long way to go before the 1:N recognition distance in practical scenarios such as video surveillance, especially when N is large. . In the future, we need to invest more energy in training data expansion, new model design and measurement learning to make large-scale face recognition come into practical use as soon as possible.
Original Electronics Technology (Suzhou) Co., Ltd. , https://www.original-te.com