An important part of using high-level synthesis to create high-quality RTL designs is to optimize C code. Vivado Hls always tries to minimize the latency of loop and funcTIon. To achieve this, it performs as many operations as possible in parallel on loop and funcTIon. For example, at the funcTIon level, advanced synthesis always tries to execute funcTIon in parallel.
In addition to these automatic optimizations, directives are used to:
(1) Execute multiple tasks in parallel, for example, multiple executions of the same function or multiple iterations of the same loop. This is the pipeline structure.
(2) Adjust the physical implementation of the array ((block RAM), functions, loops, and ports to improve data availability and help the data flow pass the design faster.
(3) Provide information about data dependencies, or lack of data dependencies, allowing for more optimizations. The final optimization is to modify the C source code to eliminate unexpected dependencies in the code, but this may limit the performance of the hardware.
The sample design used in this article is a matrix multiplier function. The goal is to process a new sample every clock cycle and implement a data flow interface.

Optimize matrix multiplier
Solution1
A matrix multiplier design is used here to show how the loop-based design can be fully optimized. The design goal is to read a sample using the FIFO interface every clock cycle while minimizing the area. This analysis includes a comparison of loop-level optimizations and methods at the function level.
Compare the use of loops and function pipeline to create a design that can handle the sample clock. Analyze the two most common reasons why design does not meet performance requirements: loops and data flow limits (or bottlenecks).
Step 1: Create and open Project
Locate the Design_Optimization lab1 folder and enter vivado_hls –f run_hls.tcl and vivado_hls –p matrixmul_prj in the Command Prompt window.
Step 2: Comprehensive analysis and design results:
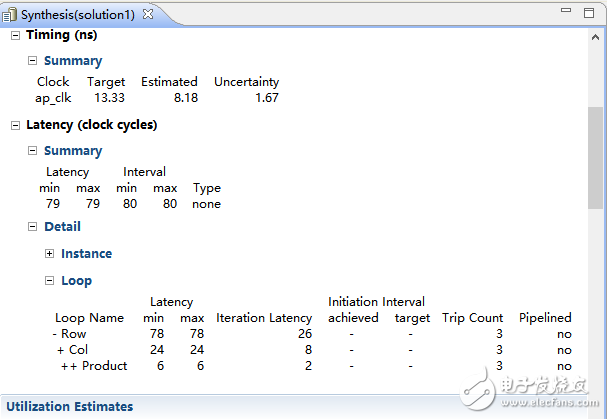
(1) In the figure, the total interval is 80 clock cycles. Because there are nine elements in each input array, it takes about nine cycles per input to be designed.
(2) The interval is one clock cycle longer than the latency, so it is not executed in parallel on the hardware.
(3)interval/latency is due to nested loops
I.Product inner loop:
- There is a delay of 2 clock cycles.
- The total iteration has 6 clock cycles.
II.COL loop:
- It requires 1 clock input and 1 clock to exit.
- It takes 8 clock cycles for each iteration (1 + 6 + 1).
- There are 24 cycles to complete all iterations.
III. The top loops require 26 clock cycles per iteration, and the total loops iterations are a total of 78 clock cycles.
In order to improve the initialization interval, you need to: pipeline loops or pipeline the entire function, and compare the two results. When pipelining loops, the initialization interval of loops is an important metric for monitoring. Even if the design reaches loop and can process a sample every clock cycle, the function's initiation interval still needs to include loops within the function to complete all data processing.
Solution2: Pipeline the Product Loop
Step 1 Create solution2, insert the pipeline directive under the Product loop (here select the pipeline under the Directive Editor)

Note: When the pipeline is nested in a loop, the biggest benefit of the innermost loop through the pipeline is that it is good for processing the sample of the data. Advanced synthesis automatically applies loop flattening, folding nested loops, and removing loop transitions (essentially creating a single loop with more iterations, but with fewer overall clock cycles).
Step 2 Comprehensive design to RTL level In the synthesis process, we get the information reported in the Console pane, showing that loop flattening is executed on loop Row. The default internal Interval target is 1 because the dependency cannot be completed on the loop product.
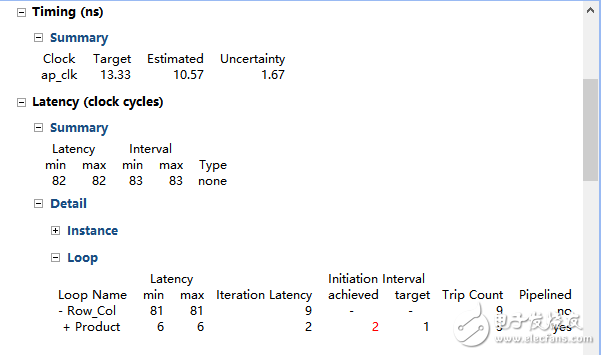
The figure shows that although the Product loop has been pipelined and the interval is 2, the top loop is not pipelined. The reason the top loop can't be pipelined is that loop flattening only happens on loop Row, and there is no loop flattening on loop Col to Product loop. The following explains why loop flattening can't flatten all nested loops.
Dust Mite Controller,Best Dust Mite Controller,Ultrasonic Dust Mite Repeller,Electronic Dust Mite Controller
Ningbo ATAP Electric Appliance Co.,Ltd , https://www.atap-airfryer.com