Tag: Entropy Code H.264
This article refers to the address: http://
The H.264/AVC recommendation is the latest video compression standard. This paper first briefly introduces the basic principles and main features of video coding standards H.261 and H.263 in image communication.
Then the key technologies in the H.264 proposal are analyzed in detail, including intra-frame inter-frame predictive coding, deblocking filtering, variable block size, multi-frame and sub-pixel motion estimation, integer DCT transform, and new entropy coding. technology.
Foreword
Image communication is a modern communication technology that has made great progress in recent years. The progress of image compression is an important part of communication development. The international standard recommends the advent of H.261, which is a summary of the research results of image coding for nearly 40 years. It solves the problem that the application of visual technology in communication has long been plagued by people, covering the image coding of audiovisual services over narrowband ISDN. It has greatly promoted the internationalization and industrialization of image communication methods such as conference television and video telephony. Subsequently, the ITU embarked on the H.263 recommendation and the latest H.264/AVC based on the H.261 recommendation. This paper first explains the basic principles of H.261 and H.263 recommendations, then explains the new technology in the new standard H.264/AVC, and finally summarizes the H.26x series of standards.
1 Basic principles of H.261 recommendations
Every image compression standard is developed for its most suitable application goals. H.261 is the earliest defined video coding standard. For the first time, it uses a combination of motion compensated predictive coding and DCT transform. The video coded signal has a transmission rate from 64 kbps to 1.92 Mbps, so it is a p×64K video encoder (p is between 1 and 31). H.261 is mainly applied to the video conferencing system on the ISDN network, and is located in the circuit switched network system. The principle of the H.261 encoder is shown in Figure 1.
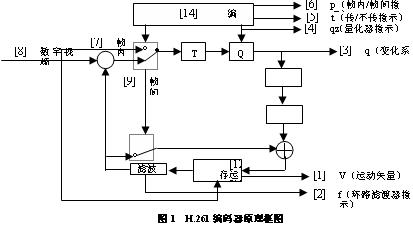
The proposal mainly uses CIF image resolution format and QCIF resolution format to solve the compatibility problem between different standard communication. For each inter-coded macroblock, H.261 uses a motion-compensated interframe prediction algorithm to eliminate correlation in the time domain of the television image; DCT transforms the prediction error to eliminate correlation in the image space domain; Adapt to the quantized DCT coefficients to make full use of human visual characteristics; then entropy coding to achieve statistical matching coding; finally use the output buffer memory to smooth the digital stream to achieve the purpose of keeping the output digital rate constant.
The proposed image frame coding mode includes I, P, and B. I frame, using intraframe coding; P frame, using interframe coding, motion compensation by I frame or previous P frame, and then encoding error estimation; B frame is bidirectionally interpolated frame without coding transmission, but I frame and P frame or P frame and PP frame interpolation reconstruction. H.261 does not support bidirectional motion prediction and GOP. Each inter-coded frame is referenced to its previous encoded frame.
The encoded data structure of the H.261 standard defines four levels from the upper layer to the bottom layer, namely the frame layer, the slice layer, the macroblock layer, and the block layer. The motion estimation compensation of H.261 is performed in units of macroblocks. For a macroblock to choose between inter-frame or intra-frame coding, you first need to judge. If it has strong correlation with the matching macroblock, the interframe coding mode may be adopted, and conversely, the intraframe coding mode is adopted.
2 Basic principles of H.263 recommendations
The H.263 standard is recommended on the basis of the H.261 standard. It achieves higher image quality without adding too much complexity at low bit rate conditions. In principle, it only takes half the bandwidth to get the same video quality as H.261. Currently, the H.263 standard has been widely adopted by various videophone terminal protocols.
The block diagram of the H.263 standard basic mode encoder is similar to the H.261 standard. Similarly, motion compensated prediction is used to reduce the temporal redundancy of the image; discrete residual cosine transform (DCT) coding is performed on the residual field of motion compensated prediction; and quantized DCT coefficients, motion vectors and additional information are obtained by variable length coding (VCL). Entropy coding is performed.
H.263 made some improvements based on the H.261 recommendations. The image size is in QCIF format, which introduces sub-CIF format and also allows CIF format. Using 8×8 DCT transform, macroblocks are uniformly quantized using the same quantization step size. One macroblock can use one motion vector, or each subblock of a macroblock can use one motion vector, thus having block motion. Compensation capability improves interframe prediction. The x-direction and y-direction of the motion vector support half-pixel precision, and the search window size of the motion estimation is limited to [-16, +15.5], and the motion vector performs differential prediction coding transmission. The coding method uses two-dimensional prediction combined with VLC coding; similar to the MPEG-1 standard, all images are divided into P frames and BP frames.
H.263 proposes to ensure better image quality under extremely low bit rate conditions. Based on H.261 hybrid coding, unrestricted motion vector mode, syntax-based arithmetic coding mode, advanced prediction mode and Encoding technology such as PB-frame mode. In the unrestricted motion vector mode, the limitation that the pixel as the reference must be within the coded image area is eliminated. Overlap motion compensation is used in advanced prediction mode, and motion vectors are also allowed to pass through motion boundaries. In the PB-frame mode, the B frame is bidirectionally predicted reconstructed by the previous decoded P frame and the current decoded P frame, which increases the frame rate but does not significantly increase the number of bits. The above three methods are mainly to improve inter prediction. The use of grammar-based arithmetic coding is to further reduce the bit rate of transmission. In this way, all the codec operations of the variable length code are replaced by arithmetically compiled operations. These advanced coding modes are provided so that the application can balance and trade off between compression performance and complexity.
3 The core technology of H.264 standard and its characteristics
H.264/AVC is the latest coding standard jointly developed by ITU-T and ISO/IEC. It was first proposed by ITU-T's VCEG in 1997. The goal is to propose a higher performance (relative to H.263 at the time). ) video coding standards.
Compared with some previous coding standards, the H.264 standard inherits the advantages of the H.263 and MPEG1/2/4 video standard protocols, but it does not change in structure, but only uses some advanced internal functional modules. Technology that improves coding efficiency. The main performance is that the encoding is no longer based on an 8×8 block, but on a 4×4 size fast, the residual transform coding is performed. The transform coding method used is no longer a DCT transform, but an integer transform coding. Context adaptive binary arithmetic coding (CABAC) with higher coding efficiency is adopted, and the corresponding quantization process is also different. The H.264 standard has the advantages of simple and easy to implement algorithm, high precision and no overflow, fast calculation speed, small memory consumption, weakening block effect, etc. It is a more practical and effective image coding standard.
The following describes the new technology of the H.264/AVC standard on top of the previous standards. The H.264 standard still uses a combination of image prediction and transform coding. The basic structure of the encoder is shown in Figure 2:
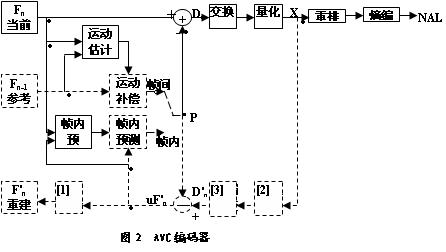
The working process of the encoder can be divided into a forward channel and a reconstruction channel according to the data flow. The encoding of the input frame Fn is to encode a macroblock of 16 × 16 pixels of the original image. Macroblock coding is divided into intra coding and inter coding. In any case, the predicted macroblock P is obtained from the reconstructed frame. In the intra coding mode, P is obtained by decoding, reconstructed prediction of the coded macroblock in the current frame, uF'n in the above figure. In the inter coding mode, P is obtained by motion compensated prediction from one or more reference frames, such as F'n-1. The difference between the predicted macroblock P and the current macroblock Fn is used as the residual macroblock Dn, and is transformed and quantized to obtain a series of transform parameters X. The parameter X needs to be processed in two aspects. One is reordering and entropy transform processing. The whole process has no feedback component, so it is called forward channel. The second is inverse quantization and inverse transform processing. The macroblock D'n is generated, and then the macro is generated. The block P is added to obtain the reconstructed macroblock uF'n, and after a series of processing, the reconstructed reference frame F'n is used for motion estimation of the next frame, so it is called a reconstruction channel.
3.1 Intra prediction coding mode
In video coding, the usual method is to divide the entire picture into several macroblocks and then encode each macroblock. Intra or Inter mode is used for encoding. In the Intra mode, the macroblock is directly DCT-transformed, and the transform coefficients are entropy encoded. This eliminates the spatial redundancy in the frame to a certain extent, but since the DCT only utilizes the correlation between the pixels inside the macroblock, it does not consider the correlation between adjacent macroblocks. H.264 introduces the Intra prediction method, which uses the correlation of adjacent macroblocks to predict the macroblock to be coded, and transforms the prediction residuals to eliminate spatial redundancy. It is worth noting that the previous standard was to make predictions in the transform domain, while H.264 was to make predictions directly in the spatial domain.
3.2 Interframe predictive coding mode
H.264 has adopted many new techniques in motion estimation, including variable block size, multi-frame motion estimation, sub-pixel precision motion estimation, and deblocking filtering.
(1) Deblocking filtering
Its role is to eliminate blockiness in the decoded image. The block effect is caused by the fact that each macroblock is separately quantized, so that at the intersection of adjacent macroblocks, the pixel values ​​that are close to each other are reconstructed due to different quantization step sizes, resulting in a large difference. boundary. The deblocking filtering is to filter on the 4x4 block boundary to make the block boundary smooth.
(2) The variable block size block size has an effect on the motion estimation. Splitting a macroblock into motion compensated sub-blocks of different sizes is called tree-structure motion compensation. The division of the macroblock and the division of the sub-macroblock each include four types, as shown in FIG. Smaller blocks can make motion estimation more accurate, resulting in smaller motion residuals and lower code rates. In the different size block selections suggested by H.264, it can be seen that one macroblock can carry up to 16 different motion vectors. In conjunction with multi-frame motion estimation, different blocks in the same macroblock can also use different reference frames for prediction.
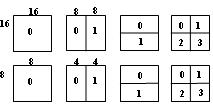
Figure 3 Motion compensated macroblock partitioning
Top: Segmentation of macroblocks
Bottom: Sub-segmentation of macroblocks
(3) Multi-frame motion estimation
Compared with the single frame motion estimation technique used in the previous video compression standard, the multiframe motion estimation used by H.264 has higher efficiency and stronger error robustness. The so-called multi-frame motion estimation refers to using one or more reference frames to estimate the motion vector, which can prevent the subsequent frames from being affected by an error in a certain frame. However, this estimation requires more memory and higher computational complexity.
(4) Sub-pixel precision motion estimation
In H.264, the accuracy of motion estimation is increased from half pixels in H.263 to pixels, and pixels are optional. As with motion estimation for half-pixel precision, motion estimation of pixel precision uses interpolation to obtain points of half-pixel and pixel position.
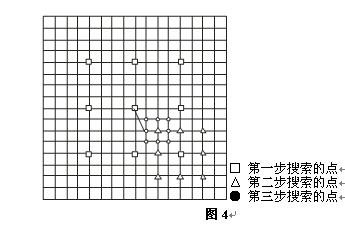
In the interframe predictive coding of H.264, the three-step search algorithm can still be used to find the block that best matches the current macroblock. In block matching, the displacement of a block is equivalent to the displacement of the center of the block or any point in the block. Therefore, the displacement of the block can be understood as the displacement of the center point. In the three-step algorithm, the search range is 7, that is, the current sub-block is used as the origin in the previous frame, and the current sub-block is moved according to a certain rule within the range of the up, down, left, and right distances of 7, and each time it moves to a position, the same is taken out. The size of the sub-block is matched with the current sub-block. Specifically divided into the following three steps:
1 With the current sub-block as the center and 4 steps, the sub-blocks centered on the 9 positions marked in FIG. 4 are matched with the current sub-block to find the best matching sub-block center position.
2 is centered on the best sub-block obtained in 1, for example, x=4, y=0, in steps of 2, matching the 9 sub-blocks centered in the figure with the current sub-block, The best matching sub-block center position.
3 is centered on the best sub-block obtained in 2, for example, x=4, y=0, in steps of 1, and the sub-blocks centered at the nine positions in the figure are matched with the current sub-block. The best matching sub-block center position, its position offset from the current sub-block center is the estimated displacement.
3.3 integer DCT transform
The H.264 standard uses a 4x4 integer DCT transform as the basic transform of the residual macroblock. The object of this transform is a 4x4 block containing residual data after motion compensated prediction or intra prediction. This type of transformation is based on a DCT transform, but is different from DCT.
Since the DCT transform is a real number, the coefficients need to be rounded off during quantization, which affects the accuracy of the operation. At the same time, the traditional DCT has a mismatch problem, and the offset of the reference frame is generated, which directly affects the quality of the reconstructed image.
All operations of the integer DCT transform proposed by H.264 use integer algorithms. The core part of the transform is mainly addition and shift. In the entire transformation and quantization process, only the 16-bit integer algorithm and one multiplication operation are performed. As long as the corresponding inverse changes are correctly used based on the H.264 recommendation, the encoder and decoder will not exhibit mismatch. Its forward and reverse transformation matrices are
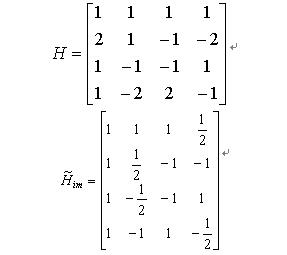
The coefficients are basically integers, and 1/2 can be replaced by shifts. In the conversion, since the multiplication can be replaced by the shift operation, the complexity is reduced and the accuracy problem is also solved.
The macroblock size in H.264 is 16×16, and after performing the above 4×4 DCT transform on each of the 4×4 size blocks, 16 4×4 transform matrices are obtained. In order to further improve the compression efficiency, the proposal also allows the DC component DC in each 4×4 transformation matrix to be separately taken out to form a new 4×4 matrix, and the matrix is ​​subjected to Hardamard transformation. The data transfer order of the macro block is as shown in FIG. 5.
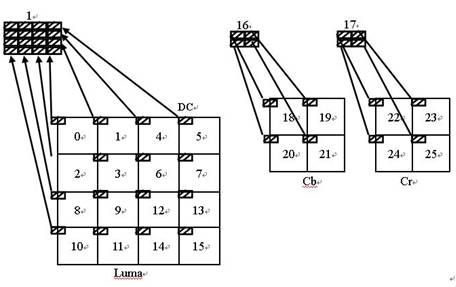
3.4 Entropy coding
H.264 recommends the use of two entropy coding modes: context-based binary arithmetic coding CABAC, and variable length coding VLC. VLC coding in turn includes context-based adaptive variable length coding CAVLC.
The CABAC method utilizes the method of arithmetic coding, and a symbol can be represented by less than 1 bit. According to the data obtained from the experiments under the assumption of error-free assumptions, CABAC performed better than CAVLC at all code rates. However, CAVLC is more error-resistant than CABAC, and the computational complexity is much lower than CABAC. Therefore, H.264 specifies the use of CAVLC in the Baseline Profile and entropy coding in the Main Profile using CABAC.
4 Summary
Compared with the previous video coding standards, H.264 proposes significant improvements in its system structure, motion estimation and motion compensation, macroblock transform and quantization, and entropy coding, with higher coding efficiency and more. Strong network adaptability. Under the same image quality, the H.264/AVC algorithm saves about 50% of the code rate over previous standards such as H.263 or MPEG-4. Different profiles of H.264 can be applied to both real-time communication and other applications where latency is not critical. In addition, the proposal adds a NAL layer that is responsible for adapting the output stream of the encoder to various types of networks, thereby providing better support for network transmission. At the same time, it has strong anti-error characteristics, and can adapt to video transmission in wireless channels with high packet loss rate and serious interference. Therefore, H.264 supports hierarchical coding transmission under different network resources, thereby obtaining smooth image quality, adapting to video transmission in different networks, and having good network affinity.
In today's Internet, the demand for multimedia services is growing rapidly. Due to the limited bandwidth resources and transmission capacity of wireless networks, most of the end users on the market currently use wireless network data services in the form of traffic payment. Improving compression efficiency is the main goal of wireless video and multimedia applications. So the H.264/AVC coding standard is the most competitive candidate for multimedia information services (MMS), packet switched streaming services (PSS) and session applications. At the same time, H.264/AVC does not have any restrictions on ownership and is a public open standard. As a result, each manufacturer's low-cost competition in the manufacturing process has been enhanced, resulting in a rapid decline in product prices, allowing the technology to serve more people.
Transient voltage suppression diode, also known as a TVS diode, is a protective electronic component that protects electrical equipment from voltage spikes introduced by wires.
TVS diodes are placed in parallel with the circuit to be protected. When its voltage exceeds the burst breakdown level, excessive current is directly shunted. TVS diodes are clamps that suppress excessive voltages that exceed their breakdown voltage. When the overvoltage disappears, the TVS diode automatically resets and absorbs much more energy than a similarly rated crowbar circuit.
TVS,TVS DIODE,Transient voltage suppression diode
Changzhou Changyuan Electronic Co., Ltd. , https://www.changyuanelectronic.com